搜索到
189
篇与
的结果
-
 Redis实现分布式锁 Redis如何做分布式锁?假设有两个服务A、B都希望获得锁,执行过程大致如下:Step1:服务A为了获得锁,向Redis发起如下命令:SET productld:lock 0xx9p03001 NXEX30000其中,"productld"由自己定义,可以是与本次业务有关的id,“0xx9p03001"是一串随机值,必须保证全局唯一,“NX"指的是当且仅当key(也就是案例中的“productld;lock'")在Redis中不存在时,返回执行成功,否则执行失败。”EX30000"指的是在30秒后,key将被自动删除。执行命令后返回成功,表明服务成功的获得了锁。Step2:服务B为了获得锁,向Redis发起同样的命令:SET productld:lock 0000111 NXEX30000由于Redis内已经存在同名key,且并未过期,因此命令执行失败,服务B未能获得锁。服务B进入循环请求状态,比如每隔1秒钟(自行设置)向Redis发送请求,直到执行成功并获得锁。Step3:服务A的业务代码执行时长超过了30秒,导致key超时,因此Redis自动删除了key。此时服务B再次发送命令执行成功,假设本次请求中设置的value值为0000222。此时需要在服务A中对key进行续期。Step4:服务A执行完毕,为了释放锁,服务A会主动向Redis发起删除key的请求。注意:在删除key之前,一定要判断服务A持有的value与Redis内存储的value是否一致。比如当前场景下,Redis中的锁早就不是服务A持有的那一把了,而是由服务2创建,如果贸然使用服务A持有的key来删除锁,则会误将服务2的锁释放掉。此外,由于删除锁时涉及到一系列判断逻辑,因此一般使用lua脚本。
Redis实现分布式锁 Redis如何做分布式锁?假设有两个服务A、B都希望获得锁,执行过程大致如下:Step1:服务A为了获得锁,向Redis发起如下命令:SET productld:lock 0xx9p03001 NXEX30000其中,"productld"由自己定义,可以是与本次业务有关的id,“0xx9p03001"是一串随机值,必须保证全局唯一,“NX"指的是当且仅当key(也就是案例中的“productld;lock'")在Redis中不存在时,返回执行成功,否则执行失败。”EX30000"指的是在30秒后,key将被自动删除。执行命令后返回成功,表明服务成功的获得了锁。Step2:服务B为了获得锁,向Redis发起同样的命令:SET productld:lock 0000111 NXEX30000由于Redis内已经存在同名key,且并未过期,因此命令执行失败,服务B未能获得锁。服务B进入循环请求状态,比如每隔1秒钟(自行设置)向Redis发送请求,直到执行成功并获得锁。Step3:服务A的业务代码执行时长超过了30秒,导致key超时,因此Redis自动删除了key。此时服务B再次发送命令执行成功,假设本次请求中设置的value值为0000222。此时需要在服务A中对key进行续期。Step4:服务A执行完毕,为了释放锁,服务A会主动向Redis发起删除key的请求。注意:在删除key之前,一定要判断服务A持有的value与Redis内存储的value是否一致。比如当前场景下,Redis中的锁早就不是服务A持有的那一把了,而是由服务2创建,如果贸然使用服务A持有的key来删除锁,则会误将服务2的锁释放掉。此外,由于删除锁时涉及到一系列判断逻辑,因此一般使用lua脚本。 -
ZooKeeper实现分布式锁原理 基于ZooKeeper的分布式锁实现原理是什么?顺序节点特性:使用ZooKeeper的顺序节点特性,假如我们在/lock/目录下创建3个节点,ZK集群会按照发起创建的顺序来创建节点,节点分别为/lock/000000000f/lock/0000000002、/lock/0000000003,最后一位数是依次递增的,节点名由zk来完成。临时节点特性:ZK中还有一种名为临时节点的节点,临时节点由某个客户端创建,当客户端与ZK集群断开连接,则该节点自动被删除。EPHEMERAL_SEQUENTIAL为临时顺序节点。根据ZK中节点是否存在,可以作为分布式锁的锁状态,以此来实现一个分布式锁,下面是分布式锁的基本逻辑:1.客户端1调用create()方法创建名为"/业务ID/lock-”的临时顺序节点。2.客户端1调用getChildren(“业务ID)方法来获取所有已经创建的子节点。3.客户端获取到所有子节点path之后,如果发现自己在步骤1中创建的节点是所有节点中序号最小的,就是看自己创建的序列号是否排第一,如果是第一,那么就认为这个客户端获得了锁,在它前面没有别的客户端拿到4.如果创建的节点不是所有节点中需要最小的,那么则监视比自己创建节点的序列号小的最大的节点,进入等待。直到下次监视的子节点变更的时候,再进行子节点的获取,判断是否获取锁。
-
ZooKeeper、Reids做分布式锁的区别 ZooKeeper和Reids做分布式锁的区别?Reids:1.Redis只保证最终一致性,副本间的数据复制是异步进行(Set是写,Get是读,Reids集群一般是读写分离架构,存在主从同步延迟情况),主从切换之后可能有部分数据没有复制过去可能会[丢失锁]情况,故强一致性要求的业务不推荐使用Reids,推荐使用zk。2.Redis集群各方法的响应时间均为最低。随着并发量和业务数量的提升其响应时间会有明显上升(公网集群影响因素偏大),但是极限qps可以达到最大且基本无异常ZooKeeper:1.使用ZooKeeper集群,锁原理是使用ZooKeeper的临时顺序节点,临时顺序节点的生命周期在Client与集群的Session结束时结束。因此如果某个Client节点存在网络问题,与ZooKeeper集群断开连接,Session超时同样会导致锁被错误的释放(导致被其他线程错误地持有),因此ZooKeeper也无法保证完全一致。2.ZK具有较好的稳定性;响应时间抖动很小,没有出现异常。但是随着并发量和业务数量的提升其响应时间和qps会明显下降。总结:1.Zookeeper每次进行锁操作前都要创建若干节点,完成后要释放节点,会浪费很多时间;2.而Redis只是简单的数据操作,没有这个问题。
-
-
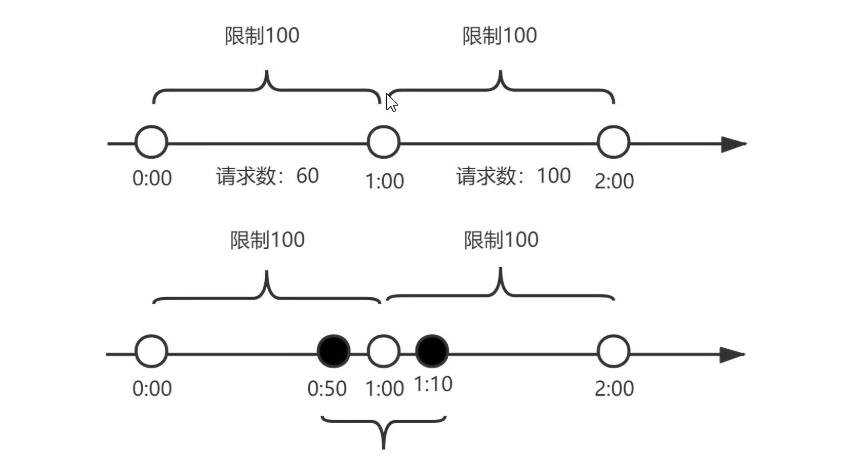
计数器算法 计数器算法是什么?计数器算法,是指在指定的时间周期内累加访问次数Ⅰ达到设定的阈值时,触发限流策略。下一个时间周期进行访问时,访问次数清零。此算法无论在单机还是分布式环境下实现都非常简单,使用redis的incr原子自增性,再结合key的过期时间,即可轻松实现。从上图我们来看,我们设置一分钟的闽值是100,在0:00到1:00内请求数是60,当到1:00时,请求数清零,从0开始计算,这时在1:00到2:00之间我们能处理的最大的请求为100,超过100个的请求,系统都拒绝。这个算法有一个临界问题,比如在上图中,在0:00到1:00内,只在0:50有60个请求,而在1:00到2:00之间,只在1:10有60个请求,虽然在两个一分钟的时间内,都没有超过100个请求,但是在0:50到1:10这20秒内,确有120个请求,虽然在每个周期内,都没超过阈值,但是在这20秒内,已经远远超过了我们原来设置的1分钟内100个请求的闽值。
-
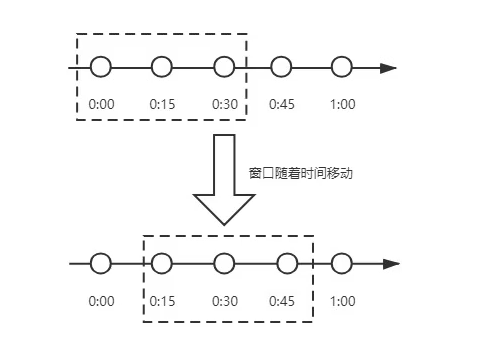
滑动时间窗口算法 滑动时间窗口算法是什么?为了解决计数器算法的临界值的问题,发明了滑动窗口算法。在TCP网络通信协议中,就采用滑动时间窗口算法来解决网络拥堵问题。I滑动时间窗口是将计数器算法中的实际周期切分成多个小的时间窗口,分别在每个小的时间窗口中记录访问次数,然后根据时间将窗口往前滑动并删除过期的小时间窗口。最终只需要统计滑动窗口范围内的小时间窗口的总的请求数即可。在上图中,假设我们设置一分钟的请求闽值是100,我们将一分中拆分成4个小时间窗口,这样,每个小的时间窗口只能处理25个请求,我们用虚线方框表示滑动时间窗口,当前窗口的大小是2,也就是在窗口内最多能处理50个请求。随着时间的推移,滑动窗口也随着时间往前移动,比如上图开始时,窗口是0:00到0:30的这个范围,过了15秒后,窗口是0:15到0:45的这个范围,窗口中的请求重新清零,这样就很好的解决了计数器算法的临界值问题。在滑动时间窗口算法中,我们的小窗口划分的越多,滑动窗口的滚动就越平滑,限流的统计就会越精确。
-
漏桶限流算法 漏桶限流算法是什么?漏桶算法的原理就像它的名字一样,我们维持一个漏斗,它有恒定的流出速度,不管水流流入的速度有多快,漏斗出水的速度始终保持不变,类似于消息中间件,不管消息的生产者请求量有多大,消息的处理能力取决于漏桶的容量=漏桶的流出速度*可接受的等待时长。在这个容量范围内的请求可以排队等待系统的处理,超过这个容量的请求,才会被抛弃。在漏桶限流算法中,存在下面几种情况:1.当请求速度大于漏桶的流出速度时,也就是请求量大于当前服务所能处理的最大极限值时,触发限流策略。2.请求速度小于或等于漏桶的流出速度时,也就是服务的处理能力大于或等于请求量时,正常执行。漏桶算法有一个缺点:当系统在短时间内有突发的大流量时,漏桶算法处理不了。
-
令牌桶限流算法 令牌桶限流算法是什么?令牌桶算法,是增加一个大小定的容器,也就是令牌桶,系统以恒定的速率向令牌桶中放入令牌,如果有客户端来请求,先需要从令牌桶中拿一个令牌,拿到令牌,才有资格访问系统,这时令牌桶中少一个令牌。当令牌桶满的时候,再向令牌桶生成令牌时,令牌会被抛弃。在令牌桶算法中,存在以下几种情况:1.请求速度大于令牌的生成速度:那么令牌桶中的令牌会被取完,后续再进来的请求,由于拿不到令牌,会被限流。2.请求速度等于令牌的生成速度:那么此时系统处于平稳状态。3.请求速度小于令牌的生成速度:那么此时系统的访问量远远低于系统的并发能力,请求可以被正常处理。令牌桶算法,由于有一个桶的存在,可以处理短时间大流量的场景。这是令牌桶和漏桶的一个区别。
-