搜索到
8
篇与
的结果
-
![[ERR] 1067 - Invalid default value for 'created_date_' [ERR]](https://minio.yanxizhu.com/blog/lazyload.jpg)
-
mysql-5.7.33-winx64.zip安装 mysql-5.7.33-winx64.zip安装一、解压到安装目录二、编写配置文件my.ini将编写好的配置文件放到mysql-5.7.33-winx64根目录下。配置文件如下:[mysql] # 设置mysql客户端默认字符集 default-character-set=utf8 [mysqld] # 设置3306端口 port = 3306 # 设置mysql的安装目录 basedir = D:\\tools\mysql-5.7.33-winx64 # 设置mysql数据库的数据的存放目录 datadir = D:\\tools\mysql-5.7.33-winx64\data # 允许最大连接数 max_connections=20 # 服务端使用的字符集默认为8比特编码的latin1字符集 character-set-server=utf8 # 创建新表时将使用的默认存储引擎 default-storage-engine=INNODB注意:1、修改自己安装路径 2、使用管理员权限执行下面的安装命令三、执行安装脚本使用管理员权限打开cmd命令工具,进入D:\tools\mysql-5.7.33-winx64\bin目录。执行安装:1、初始化,生成data文件夹.(建议使用,不设置root密码)mysqld --initialize-insecure 或者 mysqld --initialize(不建议使用,生成一个随机的root密码)2、安装MySql服务mysqld -install3、启动服务net start mysql4、设置mysql密码使用空密码进入mysql数据库,设置密码。set password for root@localhost = password('helloworld');5、环境变量配置打开电脑环境变量配置系统环境,PATH环境变量下,新增bing目录D:\tools\mysql-5.7.33-winx64\bin
-
Nacos持久化MySQL问题-解决方案 Nacos持久化MySQL问题-解决方案一、说明环境说明:MySQL:CentOS环境通过Docker部署的MySQL5.7Nacos:2.0.3原始配置:### If use MySQL as datasource: # spring.datasource.platform=mysql ### Count of DB: # db.num=1 ### Connect URL of DB: # db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC # db.user.0=nacos # db.password.0=nacos二、问题启动nacos持久化MySQL报错:/usr/local/java/jdk-11.0.10/bin/java -Xms512m -Xmx512m -Xmn256m -Dnacos.standalone=true -Dnacos.member.list= -Xlog:gc*:file=/usr/local/nacos/logs/nacos_gc.log:time,tags:filecount=10,filesize=102400 -Dloader.path=/usr/local/nacos/plugins/health,/usr/local/nacos/plugins/cmdb -Dnacos.home=/usr/local/nacos -jar /usr/local/nacos/target/nacos-server.jar --spring.config.additional-location=file:/usr/local/nacos/conf/ --logging.config=/usr/local/nacos/conf/nacos-logback.xml --server.max-http-header-size=524288 ,--. ,--.'| ,--,: : | Nacos 2.0.3 ,`--.'`| ' : ,---. Running in stand alone mode, All function modules | : : | | ' ,'\ .--.--. Port: 8848 : | \ | : ,--.--. ,---. / / | / / ' Pid: 3180 | : ' '; | / \ / \. ; ,. :| : /`./ Console: http://192.168.56.10:8848/nacos/index.html ' ' ;. ;.--. .-. | / / '' | |: :| : ;_ | | | \ | \__\/: . .. ' / ' | .; : \ \ `. https://nacos.io ' : | ; .' ," .--.; |' ; :__| : | `----. \ | | '`--' / / ,. |' | '.'|\ \ / / /`--' / ' : | ; : .' \ : : `----' '--'. / ; |.' | , .-./\ \ / `--'---' '---' `--`---' `----' 2022-10-26 12:12:21,501 INFO Bean 'org.springframework.security.access.expression.method.DefaultMethodSecurityExpressionHandler@7c8f9c2e' of type [org.springframework.security.access.expression.method.DefaultMethodSecurityExpressionHandler] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying) 2022-10-26 12:12:21,506 INFO Bean 'methodSecurityMetadataSource' of type [org.springframework.security.access.method.DelegatingMethodSecurityMetadataSource] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying) 2022-10-26 12:12:21,880 INFO Tomcat initialized with port(s): 8848 (http) 2022-10-26 12:12:22,303 INFO Root WebApplicationContext: initialization completed in 4845 ms 2022-10-26 12:12:34,613 WARN Exception encountered during context initialization - cancelling refresh attempt: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'memoryMonitor' defined in URL [jar:file:/usr/local/nacos/target/nacos-server.jar!/BOOT-INF/lib/nacos-config-2.0.3.jar!/com/alibaba/nacos/config/server/monitor/MemoryMonitor.class]: Unsatisfied dependency expressed through constructor parameter 0; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'asyncNotifyService': Unsatisfied dependency expressed through field 'dumpService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'externalDumpService': Invocation of init method failed; nested exception is ErrCode:500, ErrMsg:Nacos Server did not start because dumpservice bean construction failure : No DataSource set 2022-10-26 12:12:34,644 INFO Nacos Log files: /usr/local/nacos/logs 2022-10-26 12:12:34,644 INFO Nacos Log files: /usr/local/nacos/conf 2022-10-26 12:12:34,644 INFO Nacos Log files: /usr/local/nacos/data 2022-10-26 12:12:34,644 ERROR Startup errors : org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'memoryMonitor' defined in URL [jar:file:/usr/local/nacos/target/nacos-server.jar!/BOOT-INF/lib/nacos-config-2.0.3.jar!/com/alibaba/nacos/config/server/monitor/MemoryMonitor.class]: Unsatisfied dependency expressed through constructor parameter 0; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'asyncNotifyService': Unsatisfied dependency expressed through field 'dumpService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'externalDumpService': Invocation of init method failed; nested exception is ErrCode:500, ErrMsg:Nacos Server did not start because dumpservice bean construction failure : No DataSource set at org.springframework.beans.factory.support.ConstructorResolver.createArgumentArray(ConstructorResolver.java:769) at org.springframework.beans.factory.support.ConstructorResolver.autowireConstructor(ConstructorResolver.java:218) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.autowireConstructor(AbstractAutowireCapableBeanFactory.java:1338) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBeanInstance(AbstractAutowireCapableBeanFactory.java:1185) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:554) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:514) at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:321) at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:319) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:199) at org.springframework.beans.factory.support.DefaultListableBeanFactory.preInstantiateSingletons(DefaultListableBeanFactory.java:866) at org.springframework.context.support.AbstractApplicationContext.finishBeanFactoryInitialization(AbstractApplicationContext.java:878) at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:550) at org.springframework.boot.web.servlet.context.ServletWebServerApplicationContext.refresh(ServletWebServerApplicationContext.java:141) at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:744) at org.springframework.boot.SpringApplication.refreshContext(SpringApplication.java:391) at org.springframework.boot.SpringApplication.run(SpringApplication.java:312) at org.springframework.boot.SpringApplication.run(SpringApplication.java:1215) at org.springframework.boot.SpringApplication.run(SpringApplication.java:1204) at com.alibaba.nacos.Nacos.main(Nacos.java:35) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.base/java.lang.reflect.Method.invoke(Method.java:566) at org.springframework.boot.loader.MainMethodRunner.run(MainMethodRunner.java:49) at org.springframework.boot.loader.Launcher.launch(Launcher.java:108) at org.springframework.boot.loader.Launcher.launch(Launcher.java:58) at org.springframework.boot.loader.PropertiesLauncher.main(PropertiesLauncher.java:467) Caused by: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'asyncNotifyService': Unsatisfied dependency expressed through field 'dumpService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'externalDumpService': Invocation of init method failed; nested exception is ErrCode:500, ErrMsg:Nacos Server did not start because dumpservice bean construction failure : No DataSource set at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement.inject(AutowiredAnnotationBeanPostProcessor.java:598) at org.springframework.beans.factory.annotation.InjectionMetadata.inject(InjectionMetadata.java:90) at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor.postProcessProperties(AutowiredAnnotationBeanPostProcessor.java:376) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.populateBean(AbstractAutowireCapableBeanFactory.java:1402) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:591) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:514) at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:321) at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:319) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:199) at org.springframework.beans.factory.config.DependencyDescriptor.resolveCandidate(DependencyDescriptor.java:277) at org.springframework.beans.factory.support.DefaultListableBeanFactory.doResolveDependency(DefaultListableBeanFactory.java:1276) at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveDependency(DefaultListableBeanFactory.java:1196) at org.springframework.beans.factory.support.ConstructorResolver.resolveAutowiredArgument(ConstructorResolver.java:857) at org.springframework.beans.factory.support.ConstructorResolver.createArgumentArray(ConstructorResolver.java:760) ... 27 common frames omitted Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'externalDumpService': Invocation of init method failed; nested exception is ErrCode:500, ErrMsg:Nacos Server did not start because dumpservice bean construction failure : No DataSource set at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor.postProcessBeforeInitialization(InitDestroyAnnotationBeanPostProcessor.java:139) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsBeforeInitialization(AbstractAutowireCapableBeanFactory.java:413) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1761) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:592) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:514) at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:321) at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:319) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:199) at org.springframework.beans.factory.config.DependencyDescriptor.resolveCandidate(DependencyDescriptor.java:277) at org.springframework.beans.factory.support.DefaultListableBeanFactory.doResolveDependency(DefaultListableBeanFactory.java:1276) at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveDependency(DefaultListableBeanFactory.java:1196) at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement.inject(AutowiredAnnotationBeanPostProcessor.java:595) ... 41 common frames omitted Caused by: com.alibaba.nacos.api.exception.NacosException: Nacos Server did not start because dumpservice bean construction failure : No DataSource set at com.alibaba.nacos.config.server.service.dump.DumpService.dumpOperate(DumpService.java:236) at com.alibaba.nacos.config.server.service.dump.ExternalDumpService.init(ExternalDumpService.java:52) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.base/java.lang.reflect.Method.invoke(Method.java:566) at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor$LifecycleElement.invoke(InitDestroyAnnotationBeanPostProcessor.java:363) at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor$LifecycleMetadata.invokeInitMethods(InitDestroyAnnotationBeanPostProcessor.java:307) at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor.postProcessBeforeInitialization(InitDestroyAnnotationBeanPostProcessor.java:136) ... 53 common frames omitted Caused by: java.lang.IllegalStateException: No DataSource set at org.springframework.util.Assert.state(Assert.java:73) at org.springframework.jdbc.support.JdbcAccessor.obtainDataSource(JdbcAccessor.java:77) at org.springframework.jdbc.core.JdbcTemplate.execute(JdbcTemplate.java:371) at org.springframework.jdbc.core.JdbcTemplate.query(JdbcTemplate.java:452) at org.springframework.jdbc.core.JdbcTemplate.query(JdbcTemplate.java:462) at org.springframework.jdbc.core.JdbcTemplate.queryForObject(JdbcTemplate.java:473) at org.springframework.jdbc.core.JdbcTemplate.queryForObject(JdbcTemplate.java:480) at com.alibaba.nacos.config.server.service.repository.extrnal.ExternalStoragePersistServiceImpl.findConfigMaxId(ExternalStoragePersistServiceImpl.java:658) at com.alibaba.nacos.config.server.service.dump.processor.DumpAllProcessor.process(DumpAllProcessor.java:51) at com.alibaba.nacos.config.server.service.dump.DumpService.dumpConfigInfo(DumpService.java:293) at com.alibaba.nacos.config.server.service.dump.DumpService.dumpOperate(DumpService.java:205) ... 61 common frames omitted 2022-10-26 12:12:36,322 WARN [WatchFileCenter] start close 2022-10-26 12:12:36,322 WARN [WatchFileCenter] start to shutdown this watcher which is watch : /usr/local/nacos/data/loader 2022-10-26 12:12:36,322 WARN [WatchFileCenter] start to shutdown this watcher which is watch : /usr/local/nacos/conf 2022-10-26 12:12:36,322 WARN [WatchFileCenter] start to shutdown this watcher which is watch : /usr/local/nacos/data/tps 2022-10-26 12:12:36,322 WARN [WatchFileCenter] already closed 2022-10-26 12:12:36,322 WARN [NotifyCenter] Start destroying Publisher 2022-10-26 12:12:36,322 WARN [NotifyCenter] Destruction of the end 2022-10-26 12:12:36,323 ERROR Nacos failed to start, please see /usr/local/nacos/logs/nacos.log for more details. 2022-10-26 12:12:36,345 INFO Error starting ApplicationContext. To display the conditions report re-run your application with 'debug' enabled. 2022-10-26 12:12:36,350 ERROR Application run failed org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'memoryMonitor' defined in URL [jar:file:/usr/local/nacos/target/nacos-server.jar!/BOOT-INF/lib/nacos-config-2.0.3.jar!/com/alibaba/nacos/config/server/monitor/MemoryMonitor.class]: Unsatisfied dependency expressed through constructor parameter 0; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'asyncNotifyService': Unsatisfied dependency expressed through field 'dumpService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'externalDumpService': Invocation of init method failed; nested exception is ErrCode:500, ErrMsg:Nacos Server did not start because dumpservice bean construction failure : No DataSource set at org.springframework.beans.factory.support.ConstructorResolver.createArgumentArray(ConstructorResolver.java:769) at org.springframework.beans.factory.support.ConstructorResolver.autowireConstructor(ConstructorResolver.java:218) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.autowireConstructor(AbstractAutowireCapableBeanFactory.java:1338) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBeanInstance(AbstractAutowireCapableBeanFactory.java:1185) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:554) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:514) at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:321) at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:319) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:199) at org.springframework.beans.factory.support.DefaultListableBeanFactory.preInstantiateSingletons(DefaultListableBeanFactory.java:866) at org.springframework.context.support.AbstractApplicationContext.finishBeanFactoryInitialization(AbstractApplicationContext.java:878) at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:550) at org.springframework.boot.web.servlet.context.ServletWebServerApplicationContext.refresh(ServletWebServerApplicationContext.java:141) at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:744) at org.springframework.boot.SpringApplication.refreshContext(SpringApplication.java:391) at org.springframework.boot.SpringApplication.run(SpringApplication.java:312) at org.springframework.boot.SpringApplication.run(SpringApplication.java:1215) at org.springframework.boot.SpringApplication.run(SpringApplication.java:1204) at com.alibaba.nacos.Nacos.main(Nacos.java:35) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.base/java.lang.reflect.Method.invoke(Method.java:566) at org.springframework.boot.loader.MainMethodRunner.run(MainMethodRunner.java:49) at org.springframework.boot.loader.Launcher.launch(Launcher.java:108) at org.springframework.boot.loader.Launcher.launch(Launcher.java:58) at org.springframework.boot.loader.PropertiesLauncher.main(PropertiesLauncher.java:467) Caused by: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'asyncNotifyService': Unsatisfied dependency expressed through field 'dumpService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'externalDumpService': Invocation of init method failed; nested exception is ErrCode:500, ErrMsg:Nacos Server did not start because dumpservice bean construction failure : No DataSource set at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement.inject(AutowiredAnnotationBeanPostProcessor.java:598) at org.springframework.beans.factory.annotation.InjectionMetadata.inject(InjectionMetadata.java:90) at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor.postProcessProperties(AutowiredAnnotationBeanPostProcessor.java:376) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.populateBean(AbstractAutowireCapableBeanFactory.java:1402) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:591) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:514) at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:321) at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:319) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:199) at org.springframework.beans.factory.config.DependencyDescriptor.resolveCandidate(DependencyDescriptor.java:277) at org.springframework.beans.factory.support.DefaultListableBeanFactory.doResolveDependency(DefaultListableBeanFactory.java:1276) at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveDependency(DefaultListableBeanFactory.java:1196) at org.springframework.beans.factory.support.ConstructorResolver.resolveAutowiredArgument(ConstructorResolver.java:857) at org.springframework.beans.factory.support.ConstructorResolver.createArgumentArray(ConstructorResolver.java:760) ... 27 common frames omitted Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'externalDumpService': Invocation of init method failed; nested exception is ErrCode:500, ErrMsg:Nacos Server did not start because dumpservice bean construction failure : No DataSource set at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor.postProcessBeforeInitialization(InitDestroyAnnotationBeanPostProcessor.java:139) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsBeforeInitialization(AbstractAutowireCapableBeanFactory.java:413) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1761) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:592) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:514) at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:321) at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:319) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:199) at org.springframework.beans.factory.config.DependencyDescriptor.resolveCandidate(DependencyDescriptor.java:277) at org.springframework.beans.factory.support.DefaultListableBeanFactory.doResolveDependency(DefaultListableBeanFactory.java:1276) at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveDependency(DefaultListableBeanFactory.java:1196) at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement.inject(AutowiredAnnotationBeanPostProcessor.java:595) ... 41 common frames omitted Caused by: com.alibaba.nacos.api.exception.NacosException: Nacos Server did not start because dumpservice bean construction failure : No DataSource set at com.alibaba.nacos.config.server.service.dump.DumpService.dumpOperate(DumpService.java:236) at com.alibaba.nacos.config.server.service.dump.ExternalDumpService.init(ExternalDumpService.java:52) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.base/java.lang.reflect.Method.invoke(Method.java:566) at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor$LifecycleElement.invoke(InitDestroyAnnotationBeanPostProcessor.java:363) at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor$LifecycleMetadata.invokeInitMethods(InitDestroyAnnotationBeanPostProcessor.java:307) at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor.postProcessBeforeInitialization(InitDestroyAnnotationBeanPostProcessor.java:136) ... 53 common frames omitted Caused by: java.lang.IllegalStateException: No DataSource set at org.springframework.util.Assert.state(Assert.java:73) at org.springframework.jdbc.support.JdbcAccessor.obtainDataSource(JdbcAccessor.java:77) at org.springframework.jdbc.core.JdbcTemplate.execute(JdbcTemplate.java:371) at org.springframework.jdbc.core.JdbcTemplate.query(JdbcTemplate.java:452) at org.springframework.jdbc.core.JdbcTemplate.query(JdbcTemplate.java:462) at org.springframework.jdbc.core.JdbcTemplate.queryForObject(JdbcTemplate.java:473) at org.springframework.jdbc.core.JdbcTemplate.queryForObject(JdbcTemplate.java:480) at com.alibaba.nacos.config.server.service.repository.extrnal.ExternalStoragePersistServiceImpl.findConfigMaxId(ExternalStoragePersistServiceImpl.java:658) at com.alibaba.nacos.config.server.service.dump.processor.DumpAllProcessor.process(DumpAllProcessor.java:51) at com.alibaba.nacos.config.server.service.dump.DumpService.dumpConfigInfo(DumpService.java:293) at com.alibaba.nacos.config.server.service.dump.DumpService.dumpOperate(DumpService.java:205) ... 61 common frames omitted三、参考方案Google到许多解决方案:主要针对application.properties配置文件,数据库配置部分。### If use MySQL as datasource: spring.datasource.platform=mysql ### Count of DB: db.num=1 ### Connect URL of DB: db.url.0=jdbc:mysql://127.0.0.1:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC db.user.0=root db.password.0=root1、检查MySQL账号、密码、IP、端口是否正确。2、数据库连接是否有加时区,serverTimezone=Asia/Shanghai3、数据库版本8.0,需要在nacos下创建plugins/mysql目录,并将mysql-connector-java-8.0.23.jar放入。4、密码有特殊字符的,加单引号。5、查看防火墙端口是否放开或关闭。四、最终解决方案本地问题总结:1、Navicat连接数据库时,连接到了本地,未连接到CentOS系统。因此执行nacos脚本数据库肯定找不到。2、自己创建的数据库为nacos,而实际nacos-mysql.sql 脚本中数据库为nacos_config,因此也找不到。3、application.properties中配置的数据库名称和要和CentOS中创建的数据库名要一样,编码最好也一致。最后启动成功。/usr/local/java/jdk-11.0.10/bin/java -Xms512m -Xmx512m -Xmn256m -Dnacos.standalone=true -Dnacos.member.list= -Xlog:gc*:file=/usr/local/nacos/logs/nacos_gc.log:time,tags:filecount=10,filesize=102400 -Dloader.path=/usr/local/nacos/plugins/health,/usr/local/nacos/plugins/cmdb -Dnacos.home=/usr/local/nacos -jar /usr/local/nacos/target/nacos-server.jar --spring.config.additional-location=file:/usr/local/nacos/conf/ --logging.config=/usr/local/nacos/conf/nacos-logback.xml --server.max-http-header-size=524288 ,--. ,--.'| ,--,: : | Nacos 2.0.3 ,`--.'`| ' : ,---. Running in stand alone mode, All function modules | : : | | ' ,'\ .--.--. Port: 8848 : | \ | : ,--.--. ,---. / / | / / ' Pid: 3408 | : ' '; | / \ / \. ; ,. :| : /`./ Console: http://192.168.56.10:8848/nacos/index.html ' ' ;. ;.--. .-. | / / '' | |: :| : ;_ | | | \ | \__\/: . .. ' / ' | .; : \ \ `. https://nacos.io ' : | ; .' ," .--.; |' ; :__| : | `----. \ | | '`--' / / ,. |' | '.'|\ \ / / /`--' / ' : | ; : .' \ : : `----' '--'. / ; |.' | , .-./\ \ / `--'---' '---' `--`---' `----' 2022-10-26 12:16:14,753 INFO Bean 'org.springframework.security.access.expression.method.DefaultMethodSecurityExpressionHandler@8a2a6a' of type [org.springframework.security.access.expression.method.DefaultMethodSecurityExpressionHandler] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying) 2022-10-26 12:16:14,763 INFO Bean 'methodSecurityMetadataSource' of type [org.springframework.security.access.method.DelegatingMethodSecurityMetadataSource] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying) 2022-10-26 12:16:15,308 INFO Tomcat initialized with port(s): 8848 (http) 2022-10-26 12:16:15,818 INFO Root WebApplicationContext: initialization completed in 5099 ms WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by com.alipay.sofa.jraft.util.internal.UnsafeUtil (jar:file:/usr/local/nacos/target/nacos-server.jar!/BOOT-INF/lib/jraft-core-1.3.5.jar!/) to field java.nio.Buffer.address WARNING: Please consider reporting this to the maintainers of com.alipay.sofa.jraft.util.internal.UnsafeUtil WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release 2022-10-26 12:16:22,286 INFO Initializing ExecutorService 'applicationTaskExecutor' 2022-10-26 12:16:22,526 INFO Adding welcome page: class path resource [static/index.html] 2022-10-26 12:16:24,101 INFO Creating filter chain: Ant [pattern='/**'], [] 2022-10-26 12:16:24,133 INFO Creating filter chain: any request, [org.springframework.security.web.context.request.async.WebAsyncManagerIntegrationFilter@3313463c, org.springframework.security.web.context.SecurityContextPersistenceFilter@1bfa5a13, org.springframework.security.web.header.HeaderWriterFilter@6eed46e9, org.springframework.security.web.csrf.CsrfFilter@f849027, org.springframework.security.web.authentication.logout.LogoutFilter@76af34b5, org.springframework.security.web.savedrequest.RequestCacheAwareFilter@1da75dde, org.springframework.security.web.servletapi.SecurityContextHolderAwareRequestFilter@595fed99, org.springframework.security.web.authentication.AnonymousAuthenticationFilter@9c0d0bd, org.springframework.security.web.session.SessionManagementFilter@690df641, org.springframework.security.web.access.ExceptionTranslationFilter@6ce9771c] 2022-10-26 12:16:24,276 INFO Initializing ExecutorService 'taskScheduler' 2022-10-26 12:16:24,342 INFO Exposing 16 endpoint(s) beneath base path '/actuator' 2022-10-26 12:16:24,621 INFO Tomcat started on port(s): 8848 (http) with context path '/nacos' 2022-10-26 12:16:24,696 INFO Nacos started successfully in stand alone mode. use embedded storage
-
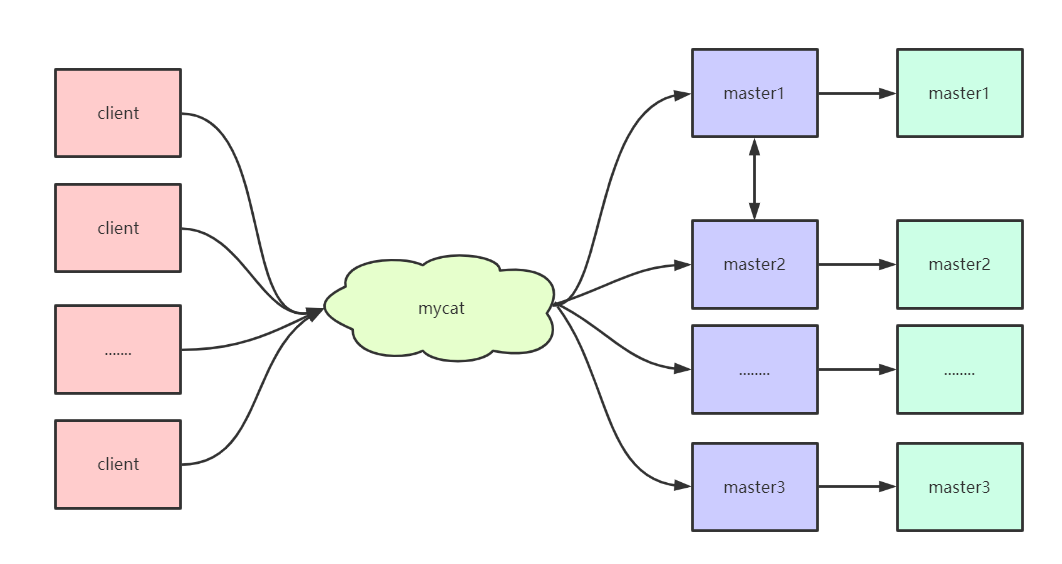
MyCat的安装及使用 MyCat的安装及使用一、MyCat的安装1、环境准备 本次课程使用的虚拟机环境是centos6.5,首先准备四台虚拟机,安装好mysql,方便后续做读写分离和主从复制。192.168.85.111 node01 192.168.85.112 node02 192.168.85.113 node03 192.168.85.114 node04 安装jdk 使用rpm的方式直接安装jdk,配置好具体的环境变量2、安装 从官网下载需要的安装包,并且上传到具体的虚拟机中,我们在使用的时候将包上传到node01这台虚拟机,由node01充当MyCat。 下载地址为:http://dl.mycat.org.cn/1.6.7.5/2020-4-10/解压文件到/usr/local文件夹下tar -zxvf Mycat-server-1.6.7.5-release-20200422133810-linux.tar.gz -C /usr/local配置环境变量vi /etc/profile 添加如下配置信息: export MYCAT_HOME=/usr/local/mycat export PATH=$MYCAT_HOME/bin:$PATH:$JAVA_HOME/bin当执行到这步的时候,其实就可以启动了,但是为了能正确显示出效果,最好修改下MyCat的具体配置,让我们能够正常进行访问。3、配置MyCat 进入到/usr/local/mycat/conf目录下,修改该文件夹下的配置文件1、修改server.xml文件<?xml version="1.0" encoding="UTF-8"?> <!-- - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - - Unless required by applicable law or agreed to in writing, software - distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the License for the specific language governing permissions and - limitations under the License. --> <!DOCTYPE mycat:server SYSTEM "server.dtd"> <mycat:server xmlns:mycat="http://io.mycat/"> <user name="root" defaultAccount="true"> <property name="password">123456</property> <property name="schemas">TESTDB</property> <property name="defaultSchema">TESTDB</property> </user> </mycat:server>2、修改schema.xml文件<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"> </schema> <dataNode name="dn1" dataHost="host1" database="msb" /> <dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="192.168.85.111:3306" user="root" password="123456"> <readHost host="hostS1" url="192.168.85.112:3306" user="root" password="123456"></readHost> </writeHost> </dataHost> </mycat:schema>4、启动mycat mycat的启动有两种方式,一种是控制台启动,一种是后台启动,在初学的时候建议大家使用控制台启动的方式,当配置文件写错之后,可以方便的看到错误,及时修改,但是在生产环境中,使用后台启动的方式比较稳妥。 控制台启动:去mycat/bin目录下执行 ./mycat console 后台启动:去mycat/bin目录下执行 ./mycat start 按照如上配置在安装的时候应该不会报错,如果出现错误,根据错误的提示解决即可。5、登录验证 管理窗口的登录 从另外的虚拟机去登录访问当前MyCat,输入如下命令即可mysql -uroot -p123456 -P 9066 -h 192.168.85.111 此时访问的是MyCat的管理窗口,可以通过show @@help查看可以执行的命令 数据窗口的登录 从另外的虚拟机去登录访问MyCat,输入命令如下:mysql -uroot -p123456 -P8066 -h 192.168.85.111 当都能够成功的时候以为着mycat已经搭建完成。二、读写分离 通过MyCat和MySQL的主从复制配合搭建数据库的读写分离,可以实现MySQL的高可用性,下面我们来搭建MySQl的读写分离。1、一主一从(主从复制的原理之前讲解过了,需要的同学自行参阅文档)1、在node01上修改/etc/my.cnf的文件#mysql服务唯一id,不同的mysql服务必须拥有全局唯一的id server-id=1 #启动二进制日期 log-bin=mysql-bin #设置不要复制的数据库 binlog-ignore-db=mysql binlog-ignore-db=information-schema #设置需要复制的数据库 binlog-do-db=msb #设置binlog的格式 binlog_format=statement2、在node02上修改/etc/my.cnf文件#服务器唯一id server-id=2 #启动中继日志 relay-log=mysql-relay3、重新启动mysql服务4、在node01上创建账户并授权slavegrant replication slave on *.* to 'root'@'%' identified by '123456'; --在进行授权的时候,如果提示密码的问题,把密码验证取消 set global validate_password_policy=0; set global validate_password_length=1;5、查看master的状态show master status6、在node02上配置需要复制的主机CHANGE MASTER TO MASTER_HOST='192.168.85.111',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=437;7、启动从服务器复制功能start slave;8、查看从服务器状态show slave status\G 当执行完成之后,会看到两个关键的属性Slave_IO_Running,Slave_SQL_Running,当这两个属性都是yes的时候,表示主从复制已经准备好了,可以进行具体的操作了2、一主一从验证 下面我们通过实际的操作来验证主从复制是否完成。--在node01上创建数据库 create database msb; --在node01上创建具体的表 create table mytbl(id int,name varchar(20)); --在node01上插入数据 insert into mytbl values(1,'zhangsan'); --在node02上验证发现数据已经同步成功,表示主从复制完成 通过MyCat实现读写分离 在node01上插入如下sql语句,-- 把主机名插入数据库中 insert into mytbl values(2,@@hostname); -- 然后通过mycat进行数据的访问,这个时候大家发现无论怎么查询数据,最终返回的都是node01的数据,为什么呢? select * from mytbl; 在之前的mycat基本配置中,其实我们已经配置了读写分离,大家还记得readHost和writeHost两个标签吗?<writeHost host="hostM1" url="192.168.85.111:3306" user="root" password="123456"> <readHost host="hostS1" url="192.168.85.112:3306" user="root" password="123456"></readHost> </writeHost> 其实我们已经配置过了这两个标签,默认情况下node01是用来完成写入操作的,node02是用来完成读取操作的,但是刚刚通过我们的验证发现所有的读取都是node01完成的,这是什么原因呢? 原因很简单,就是因为我们在进行配置的时候在 dataHost 标签中缺失了一个非常重要的属性balance,此属性有四个值,用来做负载均衡的,下面我们来详细介绍 1、balance=0 :不开启读写分离机制,所有读操作都发送到当前可用的writehost上 2、balance=1:全部的readhost和stand by writehost参与select 语句的负载均衡,简单的说,当双主双从模式下,其他的节点都参与select语句的负载均衡 3、balance=2:所有读操作都随机的在writehost,readhost上分发 4、balance=3:所有读请求随机的分发到readhost执行,writehost不负担读压力 当了解了这个参数的含义之后,我们可以将此参数设置为2,就能够看到在两个主机上切换执行了。3、双主双从 在上述的一主一从的架构设计中,很容易出现单点的问题,所以我们要想让生产环境中的配置足够稳定,可以配置双主双从,解决单点的问题。 架构图如下所示: 在此架构中,可以让一台主机用来处理所有写请求,此时,它的从机和备机,以及备机的从机复制所有读请求,当主机宕机之后,另一台主机负责写请求,两台主机互为备机。 主机分布如下:编号角色ip主机名1master1192.168.85.111node012slave1192.168.85.112node023master2192.168.85.113node034slave2192.168.85.114node04 下面开始搭建双主双从。 1、修改node01上的/etc/my.cnf文件#主服务器唯一ID server-id=1 #启用二进制日志 log-bin=mysql-bin # 设置不要复制的数据库(可设置多个) binlog-ignore-db=mysql binlog-ignore-db=information_schema #设置需要复制的数据库 binlog-do-db=msb #设置logbin格式 binlog_format=STATEMENT # 在作为从数据库的时候, 有写入操作也要更新二进制日志文件 log-slave-updates #表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1, 取值范围是1 .. 65535 auto-increment-increment=2 # 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1 .. 65535 auto-increment-offset=1 2、修改node03上的/etc/my.cnf文件#主服务器唯一ID server-id=3 #启用二进制日志 log-bin=mysql-bin # 设置不要复制的数据库(可设置多个) binlog-ignore-db=mysql binlog-ignore-db=information_schema #设置需要复制的数据库 binlog-do-db=msb #设置logbin格式 binlog_format=STATEMENT # 在作为从数据库的时候,有写入操作也要更新二进制日志文件 log-slave-updates #表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1,取值范围是1 .. 65535 auto-increment-increment=2 # 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1 .. 65535 auto-increment-offset=2 3、修改node02上的/etc/my.cnf文件#从服务器唯一ID server-id=2 #启用中继日志 relay-log=mysql-relay 4、修改node04上的/etc/my.cnf文件#从服务器唯一ID server-id=4 #启用中继日志 relay-log=mysql-relay 5、所有主机重新启动mysql服务 6、在两台主机node01,node03上授权同步命令GRANT REPLICATION SLAVE ON *.* TO 'root'@'%' IDENTIFIED BY '123456'; 7、查看两台主机的状态show master status; 8、在node02上执行要复制的主机CHANGE MASTER TO MASTER_HOST='192.168.85.111',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=154; 9、在node04上执行要复制的主机CHANGE MASTER TO MASTER_HOST='192.168.85.113',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=154; 10、启动两个从机的slave并且查看状态,当看到两个参数都是yes的时候表示成功start slave; show slave status; 11、完成node01跟node03的相互复制--在node01上执行 CHANGE MASTER TO MASTER_HOST='192.168.85.113',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=442; --开启slave start slave --查看状态 show slave status\G --在node03上执行 CHANGE MASTER TO MASTER_HOST='192.168.85.111',MASTER_USER='root',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000002',MASTER_LOG_POS=442; --开启slave start slave --查看状态 show slave status\G4、双主双从验证在node01上执行如下sql语句:create database msb; create table mytbl(id int,name varchar(20)); insert into mytbl values(1,'zhangsan'); --完成上述命令之后可以去其他机器验证是否同步成功 当上述操作完成之后,我们可以验证mycat的读写分离,此时我们需要进行重新的配置,修改schema.xml文件。 在当前mysql架构中,我们使用的是双主双从的架构,因此可以将balance设置为1 除此之外我们需要注意,还需要了解一些参数: 参数writeType,表示写操作发送到哪台机器,此参数有两个值可以进行设置: writeType=0:所有写操作都发送到配置的第一个writeHost,第一个挂了切换到还生存的第二个 writeType=1:所有写操作都随机的发送到配置的writehost中,1.5之后废弃, 需要注意的是:writehost重新启动之后以切换后的为准,切换记录在配置文件dnindex.properties中 参数switchType:表示如何进行切换: switchType=1:默认值,自动切换 switchType=-1:表示不自动切换 switchType=2:基于mysql主从同步的状态决定是否切换<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"> </schema> <dataNode name="dn1" dataHost="host1" database="msb" /> <dataHost name="host1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="192.168.85.111:3306" user="root" password="123456"> <readHost host="hostS1" url="192.168.85.112:3306" user="root" password="123456"></readHost> </writeHost> <writeHost host="hostM2" url="192.168.85.113:3306" user="root" password="123456"> <readHost host="hostS2" url="192.168.85.114:3306" user="root" password="123456"></readHost> </writeHost> </dataHost> </mycat:schema> 下面开始进行读写分离的验证--插入以下语句,使数据不一致 insert into mytbl values(2,@@hostname); --通过查询mycat表中的数据,发现查询到的结果在node02,node03,node04之间切换,符合正常情况 select * from mytbl; --停止node01的mysql服务 service mysqld stop --重新插入语句 insert into mytbl values(3,@@hostname); --开启node01的mysql服务 service mysqld start --执行相同的查询语句,此时发现在noede01,node02,node04之间切换,符合情况 通过上述的验证,我们可以得到一个结论,node01,node03互做备机,负责写的宕机切换,其他机器充作读请求的响应。 做到此处,希望大家能够思考一个问题,在上述我们做的读写分离操作,其实都是基于主从复制的,也就是数据同步,但是在生产环境中会存在很多种情况造成主从复制延迟问题,那么我们应该如何解决延迟问题,这是一个值得思考的问题,到底如何解决呢?三、数据切分 数据切分指的是通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库上面,以达到分散单台设备负载的效果。 数据的切分根据其切分规则的类型,可以分为两种切分模式。一种是按照不同的表来切分到不同的数据库之上,这种切可以称之为数据的垂直切分或者纵向切分,另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库上面,这种切分称之为数据的水平切分或者横向切分。 垂直切分的最大特点就是 规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也很小,拆分规则也会比较简单清晰。 水平切分与垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库中,对于应用程序来说,拆分规则本身就较根据表明来拆分更为复杂,后期的数据维护也会更为复杂一些。1、垂直切分 一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者压力分担到不同的库上面。 如上图所示,一个系统被切分成了用户系统、订单交易、支付系统等多个库。 一个架构设计较好的应用系统,其总体功能肯定是又多个功能模块所组成的。而每一个功能模块所需要的数据对应到数据库中就是一个或者多个表。而在架构设计中,各个功能模块相关质检的交互点越统一越少,系统的耦合度就越低,系统各个模块的维护性以及扩展性也就越好。这样的系统,实现数据的垂直切分也就越容易。 但是往往系统中有些表难以做到完全的独立,存在着跨库join的情况,对于这类的表,就需要去做平衡,是数据让步业务,共用一个数据源还是分成多个库,业务之间通过接口来做调用。在系统初期,数据量比较少,或者资源有限的情况下,会选择共用数据源,但是当数据发展到一定规模,负载很大的情况下就必须要做分割。 一般来讲业务存在着复杂join的场景是难以切分的,往往业务独立的易于切分。如何切分,切分到何种程度是考验技术架构的一个难题。下面来分析下垂直切分的优缺点: 优点: 1、拆分后业务清晰,拆分规则明确 2、系统之间整合或扩展容易 3、数据维护简单 缺点: 1、部分业务表无法实现join,只能通过接口方式解决,提高了系统复杂度 2、受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高 3、事务处理复杂2、水平切分 相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中, 拆分数据就需要定义分片规则。关系型数据库是行列的二维模型,拆分的第一原则是找到拆分维度。比如从会员的角度来分析,商户订单交易类系统中查询会员某天某月某个订单,那么就需要按照会员结合日期来拆分,不同的数据按照会员id做分组,这样所有的数据查询join都会在单库内解决;如果从商户的角度来讲,要查询某个商家某天所有的订单数,就需要按照商户id做拆分;但是如果系统既想按照会员拆分,又想按照商家数据拆分,就会有一定的困难,需要综合考虑找到合适的分片。 几种典型的分片规则包括: 1、按照用户id取模,将数据分散到不同的数据库,具有相同数据用户的数据都被分散到一个库中; 2、按照日期,将不同月甚至日的数据分散到不同的库中; 3、按照某个特定的字段求模,或者根据特定范围段分散到不同的库中。 如图,切分原则都是根据业务找到适合的切分规则分散到不同的库,下图是用用户id求模的案例: 数据做完了水平拆分之后也是有优缺点的。 优点: 1、拆分规则抽象好,join操作基本可以数据库做; 2、不存在单库大数据,高并发的性能瓶颈; 3、应用端改造较少; 4、提高了系统的稳定性跟负载能力 缺点: 1、拆分规则难以抽象 2、分片事务一致性难以解决 3、数据多次扩展跟维护量极大 4、跨库join性能较差3、总结 数据切分的两种方式,会发现每种方式都有自己的缺点,但是他们之间有共同的缺点,分别是: 1、引入了分布式事务的问题 2、跨节点join的问题 3、跨节点合并排序分页的问题 4、多数据源管理的问题 针对数据源管理,目前主要有两种思路: 1、客户端模式,在每个应用程序模块中配置管理自己需要的一个或多个数据源,直接访问各个数据库,在模块内完成数据的整合 2、通过中间代理层来统一管理所有的数据源,后端数据库集群对前端应用程序透明; 在实际的生产环境中,我们都会选择第二种方案来解决问题,尤其是系统不断变得庞大复杂的时候,其实这是非常正确的,虽然短期内付出的成本可能会比较大,但是对整个系统的扩展性来说,是非常有帮助的。 MyCat通过数据切分解决传统数据库的缺陷,又有了nosql易于扩展的优点。通过中间代理层规避了多数据源的数据问题,对应用完全透明,同时对数据切分后存在的问题,也做了解决方案。 MyCat在做数据切分的时候应该尽可能的遵循以下原则,当然这也是经验之谈,最终的落地实现还是要看具体的应用场景在做具体的分析 第一原则:能不切分尽量不要切分 第二原则:如果要切分一定要选择合适的切分规则,提前规划好 第三原则:数据切分尽量通过数据冗余或表分组来降低跨库join的可能 第四原则:由于数据库中间件对数据join实现的优劣难以把握,而且实现高性能难度极大,业务读取尽量少使用多表join。四、MyCat的配置文件讲解 在之前的操作中,我们已经做了部分文件的配置,但是具体的属性并没有讲解,下面我们讲解下每一个配置文件具体的属性以及相关的基本配置。1、搞定schema.xml文件 schema.xml作为MyCat中重要地配置文件之一,管理着MyCat的逻辑库、表、分片规则、DataNode以及DataSource。1、schema标签<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"></schema> schema标签用于定义MyCat实例中的逻辑库,MyCat可以有多个逻辑库,每个逻辑库都有自己相关的配置,可以使用schema标签来划分这些不同的逻辑库。如果不配置schame,那么所有的表配置都将属于同一个默认的逻辑库。 dataNode:该属性用于绑定逻辑库到某个具体的database上。 checkSQLschema:当该值为true时,如果执行select from TESTDB.user,那么MyCat会将语句修改为select from user,即把表示schema的字符去掉,避免发送到后端数据库执行时报错。 sqlMaxLimit:当该值设置为某个数值的时候,每次执行的sql语句,如果没有加上limit语句,MyCat也会自动加上对应的值。例如,当设置值为100的时候,那么select from user的效果跟执行select from user limit 100相同。如果不设置该值的话,MyCat默认会把所有的数据信息都查询出来,造成过多的输出,所以,还是建议设置一个具体的值,以减少过多的数据返回。当然sql语句中可以显式的制定limit的大小,不受该属性的约束。2、table标签<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" ></table> table标签定义了MyCat中的逻辑表,所有需要拆分的表都需要在这个标签中定义。 name:定义逻辑表的表名,这个名字就如同创建表的时候指定的表名一样,同个schema标签中定义的名字必须唯一。 dataNode:定义这个逻辑表所属的dataNode,该属性的值需要和dataNode标签中的name属性值对应,如果需要定义的dn过多,可以使用如下方法减少配置:<table name="travelrecord" dataNode="multipleDn$0-99,multipleDn2$100-199" rule="auto-shardinglong" ></table> <dataNode name="multipleDn$0-99" dataHost="localhost1" database="db$0-99" ></dataNode> <dataNode name="multipleDn2$100-199" dataHost="localhost1" database=" db$100-199" ></dataNode> rule:该属性用于指定逻辑表要使用的规则名字,规则名字在rule.xml中定义,必须与tableRule标签中的name属性值一一对应 ruleRequired:该属性用于指定表是否绑定分片规则,如果配置为true,但没有配置具体rule的话,程序会报错。 primaryKey:该逻辑表对应真实表的主键,例如:分片的规则是使用非主键进行分片的,那么在使用主键查询的时候,就会发送查询语句到所有配置的DN上,如果使用改属性配置真实表的主键。那么MyCat会缓存主键与具体DN的信息,那么再次使用非主键进行查询的时候就不会进行广播式的查询,就会直接发送语句到具体的DN,但是尽管配置改属性,如果缓存没有命中的话,还是会发送语句给具体的DN来获得数据 type:该属性定义了逻辑表的类型,目前逻辑表只有全局表和普通表两种类型。对应的配置: 全局表:global 普通表:不指定该值为global的所有表 autoIncrement:MySQL 对非自增长主键,使用 last_insert_id()是不会返回结果的,只会返回 0。所以,只有定义了自增长主键的表才可以用 last_insert_id()返回主键值。MyCat目前提供了自增长主键功能,但是如果对应的MySQL节点上数据表,没有定义 auto_increment,那么在MyCat层调用 last_insert_id()也是不会返回结果的。由于 insert 操作的时候没有带入分片键, MyCat 会先取下这个表对应的全局序列,然后赋值给分片键。 这样才能正常的插入到数据库中,最后使用 last_insert_id()才会返回插入的分片键值。如果要使用这个功能最好配合使用数据库模式的全局序列。使用 autoIncrement=“true” 指定这个表有使用自增长主键,这样 MyCat才会不抛出分片键找不到的异常。使用 autoIncrement=“false” 来禁用这个功能,当然你也可以直接删除掉这个属性。默认就是禁用的。 needAddLimit:指定表是否需要自动的在每个语句后面加上limit限制。由于使用了分库分表,数据量有时会特别巨大。这时候执行查询语句,如果恰巧又忘记了加上数量限制的话,那么查询所有的数据出来,就会执行很久的时间,所以mycat自动为我们加上了limit 100。当前如果语句中又limit,那么就不会添加了。3、childTable标签 childTable标签用于定义ER分片的子表。通过标签上的属性与父表进行关联。 name:定义子表的表名 joinKey:插入子表的时候会使用这个列的值查找父表存储的数据节点 parentKey:属性指定的值一般为与父表建立关联关系的列名。程序首先获取joinkey的值,再通过parentKey属性指定的列名产生查询语句,通过执行该语句得到父表存储再哪个分片上,从而确定子表存储的位置。 primaryKey:跟table标签所描述相同 needAddLimit:跟table标签所描述相同4、dataNode标签<dataNode name="dn1" dataHost="lch3307" database="db1" ></dataNode> dataNode标签定义了mycat中的数据节点,也就是我们通常说的数据分片,一个dataNode标签就是一个独立的数据分片。 name:定义数据节点的名字,这个名字需要是唯一的,我们需要再table标签上应用这个名字,来建立表与分片对应的关系 dataHost:该属性用于定义该分片属于哪个数据库实例,属性值是引用dataHost标签上定义的name属性。 database:该属性用于定义该分片属性哪个具体数据库实力上的具体库,5、dataHost标签 该标签定义了具体的数据库实例、读写分离配置和心跳语句<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM1" url="localhost:3306" user="root" password="123456"> <!-- can have multi read hosts --> <!-- <readHost host="hostS1" url="localhost:3306" user="root" password="123456" /> --> </writeHost> <!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> --> </dataHost> name:唯一标识dataHost标签,供上层的标签使用 maxcon:指定每个读写实例连接池的最大连接 mincon:指定每个读写实例连接连接池的最小链接,初始化连接池的大小 balance:负载均衡类型: 0:不开启读写分离机制,所有读操作都发送到当前可用的writeHost上 1:全部的readHost和stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡 2:所有读操作都随机的再writeHost、readHost上分发 3:所有读请求随机的分发到writeHost对应readHost执行,writeHost不负担读压力,在之后的版本中失效。 writeType:写类型 writeType=0:所有的写操作发送到配置的第一个writeHost,第一个挂了切换到还生存的第二个writeHost,重启之后以切换后的为准,切换记录保存在配置文件 dnindex.properties writeType=1:所有写操作都随机的发送到配置的writeHost,1.5以后废弃不推荐 dbType:指定后端连接的数据库类型,如MySQL,mongodb,oracle dbDriver:指定连接后端数据库使用的Driver,目前可选的值有native和JDBC。使用native的话,因为这个值执行的是二进制的mysql协议,所以可以使用mysql和maridb,其他类型的数据库则需要使用JDBC驱动来支持。 switchType:是否进行主从切换 -1:表示不自动切换 1:默认值,自动切换 2:基于mysql主从同步的状态决定是否切换6、heartbeat标签 这个标签指明用于和后端数据库进行心跳检测的语句。2、搞定server.xml文件 server.xml几乎保存了所有mycat需要的系统配置信息。<user name="test"> <property name="password">test</property> <property name="schemas">TESTDB</property> <property name="schemas">TESTDB</property> <property name="schemas">TESTDB</property> <property name="schemas">TESTDB</property> <privileges check="false"> <schema name="TESTDB" dml="0010" showTables="custome/mysql"> <table name="tbl_user" dml="0110"></table> <table name="tbl_dynamic" dml="1111"></table> </schema> </privileges> </user> server.xml中的标签本就不多,这个标签主要用于定义登录mycat的用户和权限。 property标签用来声明具体的属性值,name用来指定用户名,password用来修改密码,readonly用来限制用户是否是只读的,schemas用来控制用户课访问的schema,如果有多个的话,用逗号分隔 privileges标签是对用户的schema及下级的table进行精细化的DML控制,privileges节点的check属性适用于标识是否开启DML权限检查,默认false标识不检查,当然不配置等同于不检查 在进行检查的时候,是通过四个二进制位来标识的,insert,update,select,delete按照顺序标识,0表示未检查,1表示要检查 system标签表示系统的相关属性:属性含义备注charset字符集设置utf8,utf8mb4defaultSqlParser指定的默认解析器druidparser,fdbparser(1.4之后作废)processors系统可用的线程数,默认为机器CPU核心线程数processorBufferChunk每次分配socket direct buffer的大小默认是4096个字节processorExecutor指定NIOProcessor共享的businessExecutor固定线程池大小,mycat在处理异步逻辑的时候会把任务提交到这个线程池中 sequnceHandlerTypemycat全局序列的类型0为本地文件,1为数据库方式,2为时间戳方式,3为分布式ZK ID生成器,4为zk递增id生成3、rule.xml rule.xml里面就定义了我们对表进行拆分所涉及到的规则定义。我们可以灵活的对表使用不同的分片算法,或者对表使用相同的算法但具体的参数不同,这个文件里面主要有tableRule和function这两个标签。1、tableRule 这个标签被用来定义表规则,定义的表规则在schema.xml文件中<tableRule name="rule1"> <rule> <columns>id</columns> <algorithm>func1</algorithm> </rule> </tableRule> name属性指定唯一的名字,用来标识不同的表规则 内嵌的rule标签则指定对物理表中的哪一列进行拆分和使用什么路由算法 columns内指定要拆分的列的名字 algorithm使用function标签中的那么属性,连接表规则和具体路由算法。当然,多个表规则可以连接到同一个路由算法上。2、function<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap"> <property name="mapFile">partition-hash-int.txt</property> </function> name指定算法的名字 class指定路由算法具体的类名字 property为具体算法需要用到的一些属性
-
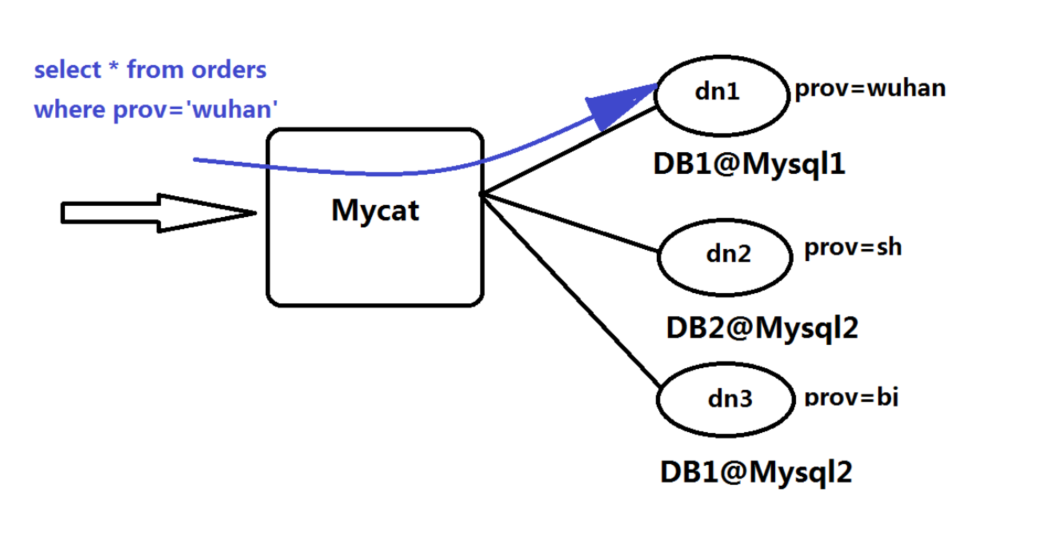
MyCat MyCat一、基础知识1、分布式系统 分布式系统是指其组件分布在网络上,组件之间通过传递消息进行通信和动作协调的系统。它的核心理念是让多台服务器协同工作,完成单台服务器无法处理的任务,尤其是高并发或者大数据量的额任务。它的特点是: 透明性:分布式系统对于用户是透明的,一个分布式系统在用户面前的表现就像一个传统的单处理机分时系统,可用用户不必了解其内部结构就能使用; 扩展性:分布式系统的最大特点是可扩展性,它能够根据需求的增加而扩展,可以通过横向扩展使集群的整体性能得到线性提升,也可以通过纵向扩展单台服务器的性能使服务器集群的性能得到提升; 可靠性:分布式系统不允许单点失效的问题存在,它的基本思想是,如果一台机器坏了,则其他机器能够接替它进行工作,具有持续服务的特性; 高性能:高性能才是设计分布式系统的初衷. 分布式系统的缺点: 1、在节点通信部分的开销比较大,线程安全问题也变得复杂,需要在保证数据完整性的同时兼顾性能 2、过分依赖网络,网络信息的丢失和饱和将会抵消分布式系统的大部分优势 3、有潜在的数据安全和网络安全等安全性问题。2、分布式数据库 随着技术的发展,各个行业所产生的数据量呈爆炸式增长,动辄就达到数百TB或者PB的级别,已经远远超过了传统单机数据库的处理能力,因此分布式数据库已经成为了最最迫切的需求。 分布式数据库是指数据在物理上分步而在逻辑上集中管理的数据库系统。物理上分步是指分布式数据库的数据分步在物理位置不同并由网络连接的节点或站点上;逻辑上集中是指各数据库节点之间在逻辑上是一个整体,并由统一的数据库管理系统管理,不同的节点分步可以跨不同的机房、城市甚至国家。 分布式数据库的特点: 透明性:用户不必关系数据的逻辑分区和物理位置分步的细节,也不必关系重复副本的一致性问题,同时不必关系在局部场地上数据库支持哪种数据模型,对于开发工程师而言,当数据库从一个场地移到另一个场地时必须改写应用程序,使用起来如果一个数据库。 数据冗余性:分布式数据库通过冗余实现系统的可靠性、可用性,并改善其性能。多个节点存储数据副本,当某一个节点的数据遭到破坏时,冗余的副本可保证数据的完整性;当工作的节点受损害时,可通过心跳等机制进行切换,系统整体不被破坏。还可以通过热点数据的就近分步原则减少网络通信的消耗,加快访问速度,改善性能。 易于扩展性:在分布式数据库中能够方便地通过水平扩展提高系统的整体性能,也能够通过垂直扩展来提高性能,扩展并不需要修改系统程序。 自治性:各节点上的数据由本地的DBMS管理,具有自治处理能力,完成本场地的应用或局部应用 分布式数据库还具有经济、性能优越、响应速度更快、灵活的体系结构、易于继承现有系统等特点。3、分布式数据库的实现原理 分布式数据库具有逻辑整体性、物理分布式,正是因为其物理分布性才使得分布式数据库的实现变得更加复杂,因为数据划分后存储在不同的节点上,而为了保证可靠性,需要存储多个副本,所以产生了数据复制的问题。为了保证良好的性能,分布式数据库必须易于扩展,具体来讲分布式数据库应有4个优势:数据分片及复制管理、具有事务的可靠性存取、良好的性能、易于扩展,所以分布式数据库在设计上需要实现数据库数据库的目录管理、数据分片、分布式查询处理、分布式并发控制、分布式锁管理、分布式存储、分布式网络架构、分布式安全管理等。 1、分布式数据库的目录管理 分布式数据库的目录存放着系统元数据及数据库的元数据的全部信息,这些数据的存在是为了正确、有效地访问数据。数据的增删改查操作都需要用到目录,用户授权、安全管理及并发控制等也都需要用到目录,目录结构的合理性直接影响数据库的性能。目录一般包括各级的描述、访问方法的描述、关于数据库的统计数据和一致性信息等,系统根据这些信息将用户查询转换为物理数据库上的查询,选择一条最佳的存取路径进行事务管理及安全性、完整性检查等。 分布式数据库的目录课分为全局目录、分布式目录、全局与本地混合目录。 2、数据分片 当数据库过于庞大,尤其是写入过于频繁且很难由一台主机支撑时,我们还是会面临扩展瓶颈。我们将存放在同一个数据库实例中的数据分散存放到多个数据库实例上,进行多台设备存取以提高性能,在切分数据的同时可以提高系统整体的可用性。 数据分片是指将数据全局地划分为相关的逻辑片段,有水平切分、垂直切分、混合切分三种类型。 水平切分:按照某个字段的某种规则分散到多个节点库中,每个节点中包含一部分数据。可以将数据的水平切分简单理解为按照数据行进行切分,就是将表中的某些行却分到一个节点,将另外某些行切分到其他节点,从分布式的整体来看它们是一个整体的表 垂直切分:一个数据库由很多表构成,每个表对应不同的业务,垂直切分是指按照业务将表进行分类并分不到不同的节点上,垂直拆分简单明了,拆分规则明确,应用程序模块清晰、明确、容易整合,但是某个表的数据量达到一定程度后扩展起来比较困难。 混合切分:水平切分和垂直切分的结合 3、分布式查询处理 分布式查询处理的任务就是把一个分布式数据库上的高层次查询映射为在本地数据库上的操作,查询的解析必须拆分为代数查询的关系运算序列,将要查询的数据定位到各节点,使得查询在各节点进行,最后通过网络通信的操作汇聚查询结果。 4、分布式并发控制 并发控制是分布式事务管理的基本任务之一,其目的是保证分布式数据库中的多个事务并发高效、正确的执行。并发控制用来保证事务的可串行性,也就是说事务的并发执行等价于它们按某种次序的串行执行,从而为用户提供并发的透明性。进行并发控制的方法主要有三种:加锁并发控制、时间戳控制、乐观并发控制。加锁并发控制应用广泛,但是容易发生死锁;时间戳控制消除了死锁,一旦发生冲突变回重启而不是等待,需要有全局的统一时钟;乐观并发控制对于冲突较少的系统较为合适,对于冲突多的系统则效率低下。4、OLTP和OLAP 在互联网时代,海量数据的存储和访问成为系统设计与使用的瓶颈,对于海量数据处理,按照使用场景,主要分为两种类型:联机事务处理(OLTP)和联级分析处理(OLAP)。 联机事务处理也称为面向事务的处理系统,其基本特征是原始数据可以立即传送到计算中心进行处理,在很短的时间内给出处理结果。 联级分析处理是指通过多维的方式对数据进行分析、查询和报表,可以同数据挖掘工具、统计分析工具配合使用,增强决策分析功能。 两者之间的区别: OLTPOLAP系统功能日常交易处理统计、分析、报表DB设计面向实时交易类应用面向统计分析类应用数据处理当前的,最新的细节的,历史的、聚集的、多维的、集成的实时性实时读写要求高实时要求读写低事务强一致性弱事务分析要求低,简单高,复杂5、关系型数据库和NoSQL 关系型数据库是建立在关系模型基础上的数据库,其借助于集合代数等数学概念和方法来处理数据库中的数据,主流的是Oracle,DB2,SQL Server,MySQL NoSQL数据库,全称为Not Only SQL,意思就是适用关系型数据库的时候就是用关系型数据库,不适用的时候也没必要非使用关系型数据库不可,可以考虑更加合适的数据存储,主要分为临时性键值存储(Memcached,Redis),永久性键值存储(Redis),面向文档的数据库(MongoDB,CouchDB),面向列的数据库(Cassandra,HBase),每种NoSQL都有其特有的使用场景及优点。 关系型数据库NoSQL数据库特点数据关系模型基于关系模型,结构化存储,完整性约束基于二维表及其之间的联系,需要连接、并、交、差等操作采用结构化的查询语言做数据读写操作需要数据的一致性,需要事务甚至强一致性非结构化的存储基于多维关系模型具有特色的使用场景优点保证数据的一致性可以进行join等复杂查询通用化,技术成熟高并发、大数据下读写能力强支持分布式,易于扩展,可伸缩简单,弱结构化存储缺点数据读写必须经过sql解析,大量数据、高并发读写性能不足对数据做读写,或修改数据结构时需要加锁,影响并发操作无法适应非结构化存储扩展困难昂贵、复杂join等复杂操作能力较弱事务支持较弱通用性差无完整约束复杂业务场景支持较差二、MyCat介绍1、MyCat是什么 MyCat 是什么?从定义和分类来看,它是一个开源的分布式数据库系统,是一个实现了 MySQL 协议的Server,前端用户可以把它看作是一个数据库代理,用 MySQL 客户端工具和命令行访问,而其后端可以用MySQL 原生(Native) 协议与多个 MySQL 服务器通信,也可以用 JDBC 协议与大多数主流数据库服务器通信,其核心功能是分表分库,即将一个大表水平分割为 N 个小表,存储在后端 MySQL 服务器里或者其他数据库里。 MyCat 发展到目前的版本,已经不是一个单纯的 MySQL 代理了,它的后端可以支持 MySQL、 SQL Server、Oracle、 DB2、 PostgreSQL 等主流数据库,也支持 MongoDB 这种新型 NoSQL 方式的存储,未来还会支持更多类型的存储。而在最终用户看来,无论是那种存储方式,在 MyCat 里,都是一个传统的数据库表,支持标准的SQL 语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度,在测试阶段,可以将一个表定义为任何一种 MyCat 支持的存储方式,比如 MySQL 的 MyASIM 表、内存表、或者MongoDB、 LevelDB 以及号称是世界上最快的内存数据库 MemSQL 上。试想一下,用户表存放在 MemSQL 上,大量读频率远超过写频率的数据如订单的快照数据存放于 InnoDB 中,一些日志数据存放于 MongoDB 中,而且还能把 Oracle 的表跟 MySQL 的表做关联查询,你是否有一种不能呼吸的感觉?而未来,还能通过 MyCat 自动将一些计算分析后的数据灌入到 Hadoop 中,并能用 MyCat+Storm/Spark Stream 引擎做大规模数据分析,看到这里,你大概明白了, MyCat 是什么? MyCat 就是 BigSQL, Big Data On SQL Database。 对于不同的角色,MyCat到底是个啥? 对于DBA而言,可以这么理解MyCat: MyCat就是MySQL Server,而Mycat后面连接的MySQL Server,就好像是MySQL的存储引擎,如InnoDB,MyISAM等,因此,MyCat本身并不存储数据,数据是再后端的MySQL上存储的,因此数据可靠性以及事务都是MySQL保证的,简单说,MyCat就s是MySQL最佳伴侣,它再一定程度上让MySQL拥有了能跟Oracle PK的能力。 对于软件工程师来说,可以这么理解MyCat: MyCat就是一个近似等于MySQL的数据库服务器,你可以用连接MySQL的方式去连接MyCat,除了端口不同,默认的MyCat端口是8066而不是MySQL的3306,因此需要再连接字符串上增加端口信息,大多数情况下,可以用你熟悉的对象映射框架使用MyCat,但建议对于分片表,尽量使用基础的SQL语句,因为这样能达到最佳性能,特别是几千万甚至几百亿条记录的情况下。 对于架构师来说,可以这么理解MyCat: MyCat是一个强大的数据库中间件,不仅仅可以用作读写分离、以及分库分表、容灾备份,而且可以用于多租户应用开发,云平台基础设施,让你的架构具备很强的适应性和灵活性,借助于即将发布的mycat只能优化模块,系统的数据访问瓶颈和热点一目了然,根据这些统计分析数据,你可以自动或手工调整后端存储,将不同的表映射到不同的存储引擎上,而整个应用的代码一行也不用改变。2、MyCat的原理 MyCat的原理并不复杂,复杂的是代码,如果代码也不复杂,那么早就成为了一个传说了。 MyCat的原理中最重要的一个动作是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发送后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。 上述图片里,orders表被分为了三个分片DataNode(简称dn),这三个分片是分布在两台MySQL Server上(Datahost),即datanode=database@datahost方式,因此你可以用一台到N台服务器来分片,分片规则为(sharding rule)典型的字符串枚举分片规则,一个规则的定义是分片字段(sharding column)+分片函数(rule function),这里的分片字段为prov而分片函数为字符串枚举方式。 当MyCat收到一个SQL时,会先解析这个SQL,查找涉及到的表,然后看此表的定义,如果有分片规则,则获取到SQL里分片字段的值,并分配分片函数,得到该SQL对应的分片列表,然后将SQL发往这些分片去执行,最后收集和处理所有分片返回的结果数据,并输出到客户端,以select * from orders where prov = ?语句为例,查到prov=wuhan,按照分片函数,wuhan返回dn1,于是sql就发给了mysql1,去取db1上的查询结果,并返回给用户。 如果上述sql改为select * from orders where prov in (wuhan,beijing),那么,sql就会发给MySQL1和MySQL2去执行,然后结果集合并后输出给用户。但通常业务中我们的SQL会有order by以及limit翻页语法,此时就设计到结果集在MyCat端的二次处理,这部分代码也比较复杂,而最复杂的则属两个表的join,为此,MyCat提出了创新性的ER分片,全局表,HBT(human brain tech)人工智能的Catlet,以及结合Storm/Spark引擎等十八般武艺的解决办法,从而称为目前业界最强大的方案,这就是开源的力量。3、应用场景 MyCat发展到现在,使用的场景已经很丰富,而且不断有新用户给出新的创新性的方案,以下是典型的应用场景: 1、单纯的读写分离,此时配置最为简单,支持读写分离,主从切换 2、分库分表,对于超过1000万的表进行分片,最大支持1000亿的单表分片 3、多租户应用,每个应用一个库,但应用程序只连接MyCat,从而不改造程序本身,实现多租户化 4、报表系统,借助MyCat的分表能力,处理大规模报表的统计 5、整合多数据源 6、作为海量数据实时查询的一种简单有效方案,比如100亿条频繁查询的记录需要在3秒内查询出来结果,除了基于主键的查询,还可能存在范围查询或其他属性查询,此时MyCat可能是最简单有效的选择 7、数据库路由器,MyCat基于MySQL实例的连接池复用机制,可以让每一个应用最大程度地共享一个MySQL实例的所有连接池,让数据库的并发访问能力大大提升4、为什么使用MyCat 1、java与数据库紧耦合 2、高访问量高并发对数据库的压力 3、读写请求数据不一致5、数据库中间件对比对比项目mycatmangocobarheisenbergaltasamoeba数据切片支持支持支持支持支持支持读写分离支持支持支持支持支持支持宕机自动切换支持不支持支持不支持半支持,影响写不支持mysql协议前后端支持JDBC前端支持前后端支持前后端支持JDBC支持的数据库mysql,oracle,mongodb,postgresqlmysqlmysqlmysqlmysqlmysql,mongodb社区活跃度高活跃停滞低中等停滞文档资料极丰富较齐全较齐全较少中等缺少是否开源开源开源开源开源开源开源是否支持事务弱XA支持单库强一致,分布式弱事务单库强一致,多库弱事务单库强一致,分布弱事务不支持三、MyCat的核心概念 MyCat是数据库中间件,就是介于数据库与应用之间,进行数据处理和交互的中间服务。从原有的一个库,被切分为多个分片数据库,所有的分片数据库集群构成了整个完整的数据库存储。 如上图所示,数据被分到多个分片数据库之后,应用如果需要读取数据,就要处理多个数据源的数据。如果没有数据库中间件,那么应用将直接面对分片集群,数据源切换、事务处理、数据聚合都需要应用直接处理,原本该是专注于业务的应用,将会话大量的工作来处理分片后的问题,最重要的是每个应用处理将是完全的重复造轮子。1、逻辑库 对于实际应用而言,其实并不需要知道中间件的存在,开发人员只需要知道数据库的概念即可,所以数据库中间件可以被看作是一个或多个数据库集群构成的逻辑库。 在云计算时代,数据库中间件可以以多租户的形式给一个或多个应用提供服务,每个应用访问的可能是一个独立或者共享的物理库,常见的如阿里云数据库服务器RDS2、逻辑表 既然有逻辑库,那么就应该有逻辑表,在分布式数据库中,对应用来说,读写数据的表就是逻辑表。逻辑表可以使数据切分后,分步在一个或多个分片库中,也可以不做数据切分,不分片,只有一个表构成3、分片表 分片表,是指哪些原有的很大数据的表,需要切分到多个数据库的表,这样每一个分片都会有一部分数据,所有分片构成了完整的数据。4、非分片表 一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。5、ER表 关系型数据库是基于实体关系模型之上,通过其描述了真实世界中事物与关系,MyCat中的ER表既是来源于此。根据这一思路,提出了基于ER关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上,即子类依赖于父类,通过表分组保证数据join不会跨库操作。 表分组是解决跨分片数据join的一种很好的思路,也是数据切分规划的重要一条规则。6、全局表 一个真实的业务系统中,往往存在大量的类似字典表的表,这些表基本上很少变动,字典表具有以下几个特点: 1、变动不频繁 2、数据量总体变化不大 3、数据规模不大,很少有超过数十万条记录 对于这类的表,在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较棘手的问题,所以MyCat中通过数据冗余来解决这类表的join,即所有的分片都有一份数据的拷贝,所有将字典表或者符合字典表特性的一些表定义为全局表。 数据冗余是解决跨分片数据join的一种很好思路,也是数据切分规划的另外一条重要原则7、分片节点(dataNode) 数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节点(dataNode)8、节点主机(dataHost) 数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。9、分片规则 数据切分是指一个大表被分成若干个分片表,就需要一定的规则,这样按照某种规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度。10、全局序列号 数据切分后,原有的关系数据库中的主键约束在分布式条件下将无法使用,因此需要引入外部机制保证数据唯一性标识,这种保证全局性的数据唯一标识的机制就是全局序列号。11、多租户 多租户技术或称多重租赁技术,是一种软件架构技术,它是在探讨与实现如何于多用户的环境下共用相同的系统或程序组件,并且扔可确保各用户间数据的隔离性。在云计算时代,多租户技术在共用的数据中心以单一系统架构与服务提供多数客户端相同甚至可定制化的服务,并且仍然可以保障客户的数据隔离。目前各种各样的云计算服务就是这类技术范畴,例如阿里云数据库服务(RDS),阿里云服务器等等。 多租户在数据存储上存在三种主要的方案,分别是:1、独立数据库 一个租户一个数据库,这种方案的用户数据隔离级别最高,安全性最好,但成本也高。 优点:为不同的租户提供独立的数据库,有助于简化数据模型的扩展设计,满足不同租户的独特需求,如果出现故障,恢复数据比较简单。 缺点:增大了数据库的安装数量,随之带来维护成本和购置成本的增加2、共享数据库,隔离数据架构 多个或者所有租户共享database,但是每一个租户一个schema 优点:为安全性要求较高的租户提供了一定程度的逻辑数据隔离,并不是完全隔离;每个数据库可以支持更多的租户数量 缺点:如果出现故障,数据恢复比较困难,因此恢复数据库将牵扯到其他租户的数据,如果需要跨租户统计数据,存在一定困难3、共享数据库,共享数据结构 租户共享同一个database,同一个schema,但在表中通过tenantID区分租户的数据。这是共享程度最高、隔离级别最低的模式 优点:维护和购置成本最低,运行每个数据库支持的租户数量最多 缺点:隔离级别最低,安全性最低,需要在设计开发时加大对安全的开发量,数据备份和恢复最困难,需要逐表逐条备份和还原。
-
MySQL优化 索引一、全表扫描没有使用索引的时候,数据的查询需要进行多次IO读写,这样的性能较差——全表扫描的过程。二、索引为数据库的某个字段创建索引,相当是为这个字段的内容创建了一个目录。通过这个目录可以快速的实现数据的定位,也就是通过索引能够快速的找到某条数据所在磁盘的位置。三、索引存放位置InnoDB存储引擎的表:将索引和数据存放在同一个文件里。(为什么?有什么优势?)*ibdMyISAM存储引擎的表:索引和数据分开两个文件来存储。 索引:*.MYI; 数据:MYD四、索引分类1、主键索引:主键自带索效果,也就意味着通过主键来查询表中的记录,性能是非常好的。2、普通索引:为普通列创建的索引。索引名一般格式: **idx_字段名** create index 索引名 on 表明(字段); 例子: create index idx_participant_ on cal_resource_permission(participant_);3、唯一索引:就像是唯一列,列中的数据是唯一的。比普通索引的性能要好。唯一索引名称:idx_unique_列明 create unique index 唯一索引名称 on 表明(列名); 例子: create unique index idx_unique_resource_id_ on cal_resource_permission(resource_id_);4、联合索引(组合索引):一次性为表中的多个字段一起创建索引,最左前缀法则(如何命中联合索引中的索引列)。注意:一个联合索引建议不要超过5个列格式:联合索引名一般格式: idx_字段1_字段2_字段3 create index 联合索引名 on 表明(字段1,字段2,字段3); 例子: create index idx_resource_scope_type on cal_resource_permission(resource_id_,scope_,type_id_);5、全文索引:进行查询的时候,数据源可能来自于不同的字段或者不同的表。比如去百度中查询数据,yanxizhu,来自于网页的标题或者网页的内容。MyISAM存储引擎支持全文索引。在实际生产环境中,并不会使用MySQL提供的MyISAM存储引擎的全文索引功能来是实现全文查找。而是会使用第三方的搜索引擎中间件比如ElasticSearch(比较多)、Solr。索引使用的数据结构使用索引查找数据性能很快,避免了全表扫描的多次磁盘IO读写。但是我们发现,使用索引实际上也需要在索引中查找数据,而且数据量是一样的,那么凭什么索引就能快呢?这就跟索引使用了哪种数据结构支持快速查找。什么叫数据结构:存放数据的结构。比如:数组、链表、栈、堆、队列等等这些概念。一、线性表线性的维护数据的顺序。对于线性表来说,有两种数据结构来支撑:线性顺序表:相邻两个数据的逻辑关系和物理位置是相同的。线性链式表:相邻两个数据的逻辑关系和物理存放位置没有关系。数据是有先后的逻辑关系,但是数据的物理存储位置并不连续。线性链式表又分为单项链表和双向链表:单向链表:能够通过当前结点找到下一个节点的位置,以此来维护链表的逻辑关系结点结构:数据内容+下一个数据的指针双向链表:能够通过当前结点找到上一个或下一个节点的位置,双向都可找。结点结构:上一个数据的指针+数据内容+下一个数据的指针。时间复杂度(比较次数)/空间复杂度(算法需要使用多少个变量空间)顺序表和链式表的区别:顺序表--数组:进行数据的查询性能(可以通过数组的索引/下标),数组的查询性能非常好,时间复杂度是0(1)数组的增删性能是非常差。链式表--链表:查询的性能是非常差的:时间复杂度是O(n),增删性能是非常好。二、栈、队列、串、广义表栈分为:顺序栈、链式栈顺序栈链式栈栈特点:先进后出,FIFO。队列分为:顺序队列、链式队列顺序队列链式队列队列特点:先进先出。串:String定长串、StringBuffer/Stringbuilder动态串广义表:更加灵活的多维数组,可以在不同的元素中创建不同的维度的数组。树查找树的查找性能是明显比线性表的性能要好,有这么几种树:多叉树、二叉树、二又查找树、平衡二叉树、红黑树、B树、B+树一、多叉树:非二叉树二、二叉树:一个结点最多只能有2个子结点,可以是0、1、2子结点。三、二叉查找树:二又查找树的查找性能是ok的。查询性能跟树的高度有关,树的高度又根你插入数据的顺序有关系。特点:二又树的根结点的数值是比所有左子树的结点的数值大,比右子树的几点的数值小。这样的规律同样满足于他的所有子树。四、平衡二又树,又称为AVL树实际上就是遵循以下两个特点的二叉树:每棵子树中的左子树和右子树的深度差不能超过1;二叉树中每棵子树都要求是平衡二叉树;其实就是在二又树的基础上,若树中每棵子树都满足其左子树和右子树的深度差都不超过1,则这棵二又树就是平衡二又树。二又排序树转化为平衡二叉树为了排除动态查找表中不同的数据排列方式对算法性能的影响,需要考虑在不会破坏二又排序树本身结构的前提下,将二又排序树转化为平衡二叉树,左旋、右旋、双向(先左后右、先右后左)。五、红黑树红黑树是一种特化的AVL树(平衡二叉树)(平衡二叉树的一种体现),都是在进行插入和删除操作时通过特定操作保持二又查找树的平衡,从而获得较高的查找性能。在二又查找树强制一般要求以外,对于任何有效的红黑树我们增加了如下的额外要求:性质1.结点是红色或黑色。性质2.根结点是黑色。性质3.不可能有连在一起的红色节点。性质4.每个红色结点的两个子结点都是黑色。叶子结点都是黑色(nil-黑色的空节点)这些约束强制了红黑树的关键性质:从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。结果是这个树大致上是平衡的。因为操作比如插入、删除和查找某个值的最坏情况时间都要求与树的高度成比例,这个在高度上的理论上限允许红黑树在最坏情况下都是高效的,而不同于普通的二叉查找树。平衡二又树为了维护树的平衡,在一旦不满足平衡的情况就要进行自旋,但是自旋会造成一定的系统开销。因此红黑树在自旋造成的系统开销和减少查询次数之间做了权衡。因此红黑树有时候并不是一颗平衡二叉树。红黑树已经是在查询性能上得到了优化,但索引依然没有使用红黑树作为数据结构来存储数据,因为红黑树在每一层上存放的数据内容是有限的,导致数据量一大,树的深度就变得非常大,于是查询性能非常差。因此索引没有使用红黑树。六、B树B树允许一个结点存放多个数据。这样可以使更小的树的深度来存放更多的数据。但是,B树的一个结点中到底能存放多少个数据,决定了树的深度。七、B+树特点:非叶子结点冗余了叶子结点中的键。叶子结点是从小到大、从左到右排列的。叶子结点之间提供了指针,提高了区间访问的性能。只有叶子结点存放数据。非叶子结点是不存放数据的,只存放键。八、哈希表(散列表)使用哈希表来存取数据的性能是最快的,O(1),但是不支持范围查找(区间访问)。InnoDB和MyISAM的区别InnoDB和MyISAM都是数据库表的存储引擎。那么在互联网公司,或者追求查询性能的场景下,都会使用lnnoDB作为表的存储引擎。为什么?1、InnoDB引擎把索引和数据存放在一个文件中,通过找到索引后就能直接在索引树上得叶子节点中获取完整得数据。------聚集索引可以实现行锁/表锁。2、MyISAM存储引擎把索引和数据存放在两个文件中,查找到索引后还要去另一个文件中找数据,性能会慢一些——非聚集索引。除此之外,MyISAM天然支持表锁,而且支持全文索引。|关键点:InnoDB聚集索引与MyISAM-非聚集索引面试题1.问题一:为什么非主键索引的叶子节点存放的数据是主键值如果普通索引中不存放主键,而存放完整数据,那么就会造成:数据冗余:虽然提升了查询性能,但是需要更多的空间来存放冗余的数据维护麻烦:一个地方修改数据,需要在多棵索引树上修改。2.问题二:为什么InnoDB表必须创建主键创建InnoDB表不使用主键能创建成功吗?如果能创建功能,能不能为这张表的普通列创建索引?如果没有主键,MySQL优化器会给一个虚拟的主键,于是普通索引会使用这个虚拟主键——也会造成性能开销。为了性能考虑,和设计初衷,那么创建表的时候就应该创建主键。3.问题三:为什么使用主键时推荐使用整型的自增主键1)为什么要使用整型:主键-主键索引树-树里的叶子结点和非叶子结点的键存放的是主键的值,而且这颗树是一个二又查找树。数据的存放是有大小顺序的。·整型:大小顺序是很好比较的·字符串:字符串的自然顺序的比较是要进行一次编码成为数值后再进行比较的。(字符串的自然顺序,AZ)uuid随机字符串2)为什么要自增:如果不用自增:(1016。200。18。29)使用不规律的整数来作为主键,那么主键索引树会使用更多的自旋次数来保证树索引树的叶子节点中的数据是从小到大-从左到右排列,因此性能必然比使用了自增主键的性能要差!联合索引和最左前缀法则1.联合索引的特点在使用一个索引来实现多个表中字段的索引效果。2.联合索引是如何存储的3.最左前缀法则最左前缀法则是表示一条sql语句在联合索引中有没有走索引(命中索引/不会全表扫描)#创建联合索引 create index idx_name_repaymentAmount_userName on pay(name,repaymentAmount,userName); #sql是否走联合索引 select * from pay where name="早餐"; //走索引 select * from pay where name="早餐" and repaymentAmount=5.50; //走索引 select * from pay where name="早餐" and repaymentAmount=5.50 and userName="邓凌"; //走索引 select * from pay where repaymentAmount=5.50; //不走索引 select * from pay where name="早餐" and userName="邓凌"; //走一个索引 select * from pay where userName="邓凌"; //不走索引 select * from pay where name="早餐" and userName="邓凌" and repaymentAmount=5.50 ; //走索引,因为mysql内部有优化器SQL优化SQL优化的目的是为了SQL语句能够具备优秀的查询性能,实现这样的目的有很多的途径:工程优化如何实现:数据库标准、表的结构标准、字段的标准、创建索引SQL语句的优化:当前SQL语句有没有命中索引。一、工程优化基础规范表存储引擎必须使用InnoDB表字符集默认使用utf8,必要时候使用utf8mb4通用,无乱码风险,汉字3字节,英文1字节utff8mb4是utf8的超集,有存储4字节例如表情符号时,使用它禁止使用存储过程,视图,触发器,Event对数据库性能影响较大,互联网业务,能让站点层和服务层干的事情,不要交到数据库层调试,排错,迁移都比较困难,扩展性较差禁止在数据库中存储大文件,例如照片,可以将大文件存储在对象存储系统,数据库中存储路径禁止在线上环境做数据库压力测试测试,开发,线上数据库环境必须隔离命名规范库名,表名,列名必须用小写,采用下划线分隔 tb_book t_bookabc,Abc,ABC都是给自己埋坑库名,表名,列名必须见名知义,长度不要超过32字符tmp,wushan谁TM知道这些库是干嘛的库备份必须以bak为前缀,以日期为后缀从库必须以-s为后缀备库必须以-ss为后缀表设计规范单实例表个数必须控制在2000个以内·单表分表个数必须控制在1024个以内表必须有主键,推荐使用UNSIGNED整数为主键删除无主键的表,如果是row模式的主从架构,从库会挂住禁止使用物理外键,如果要保证完整性,应由应用程式实现外键使得表之间相互耦合,影响 update/delete等SQL性能,有可能造成死锁,高并发情况下容易成为数据库瓶颈建议将大字段,访问频度低的字段拆分到单独的表中存储,分离冷热数据(具体参考:《如何实施数据库垂直拆分》)列设计规范根据业务区分使用tinyint/int/bigint,分别会占用1/4/8字节根据业务区分使用char/varchar字段长度固定,或者长度近似的业务场景,适合使用char,能够减少碎片,查询性能高字段长度相差较大,或者更新较少的业务场景,适合使用varchar,能够减少空间根据业务区分使用datetime/timestamp前者占用5个字节,后者占用4个字节,存储年使用YEAR,存储日期使用DATE,存储时间使用datetime必须把字段定义为NoT NULL并设默认值NULL的列使用索引,索引统计,值都更加复杂,MySQL 更难优化NULL需要更多的存储空间NULL只能采用Is NUL或者IS NoT NULL,而在=/!=/in/not in 时有大坑使用INT UNSIGNED存储IPv4,不要用char(15)使用varchar(20)存储手机号,不要使用整数牵扯到国家代号,可能出现+/-/()等字符,例如+86手机号不会用来做数学运算varchar 可以模糊查询,例如like'138%'使用TINYINT来代替ENUM。ENUM增加新值要进行DDL操作索引规范唯一索引使用uniq_[字段名]来命名非唯一索引使用idx_[字段名]来命名单张表索引数量建议控制在5个以内互联网高并发业务,太多索引会影响写性能生成执行计划时,如果索引太多,会降低性能,并可能导致MySQL 选择不到最优索引异常复杂的查询需求,可以选择Es等更为适合的方式存储组合索引字段数不建议超过5个如果5个字段还不能极大缩小row范围,八成是设计有问题不建议在频繁更新的字段上建立索引非必要不要进行JoIN查询,如果要进行JoIN查询,被JorN的字段必须类型相同,并建立索引踩过因为JoIN字段类型不一致,而导致全表扫描的坑么?理解组合索引最左前缀原则,避免重复建设索引,如果建立了(a,b,c),相当于建立了(a),(a,b),(a,b,c)二、Explain执行计划--SQL优化神奇1、Explain介绍在完成工程结构的优化之后,数据库、表、表中的字段及表的索引,都能够支持海量数据的快速查找。但是查找依然需要通过SQL语句来实现,因此性能优秀的SQL语句是能够走索引,快速查找到数据的。性能不Ok的SQL语句,就不会走索引,导致全表扫描。阿里云rds提供了慢sql的查询功能。找到慢SQL后,如何做优化,以及如何查询一条SQL语句是否是慢SQL,那就可以通过Explain工具。通过在SQL语句前面加上Explain关键来执行,于是就能看出当前SQL语句的执行性能。得知道当前系统里有哪些SQL是慢SQL,查询性能超过1s的sql,然后再通过Explain工具可以对当前SQL语句的性能进行判断——为什么慢,怎么解决。要想知道哪些SQL是慢SQL,有两种方式,一种是开启本地MySQL的慢查询日志;另一种是阿里云提供的RDS(第三方部署的MySQL服务器),提供了查询慢SQL的功能。explain select * from pay where name like "早%";2、MySQL内部优化器在SQL查询开始之前,MySQL内部优化器会进行一次自我优化,让这一次的查询性能尽可能的好。查看内部优化器优化后结果:explain select * from pay where name like "早%"; show WARNINGS;内部优化器优化后结果:/* select#1 */ select `family`.`pay`.`id` AS `id`,`family`.`pay`.`name` AS `name`,`family`.`pay`.`repaymentAmount` AS `repaymentAmount`,`family`.`pay`.`repaymentTime` AS `repaymentTime`,`family`.`pay`.`repaymentUser` AS `repaymentUser`,`family`.`pay`.`userName` AS `userName`,`family`.`pay`.`updateTime` AS `updateTime`,`family`.`pay`.`description` AS `description` from `family`.`pay` where (`family`.`pay`.`name` like '早%')3、Explain细节关闭MySQL对衍生表的优化:set session optimizer_switch='derived_merge=off'一、select_type该列描述了查询的类型:simple:简单查询primary:外部的主查询derived:在from后面进行的子查询,会产生衍生表subquery:在from的前面进行的子查询union:进行的联合查询explain select (select 1 from type where id=1) from (select * from pay where id=1) des; show WARNINGS;结果:derived##第一条执行sql select * from pay where id=1第一条执行的sql是from后面的子查询,该子查询只要在from后面,就会生成一张衍生表,因此他的查询类型:derivedsubqueryselect 1 from type where id=1在select之后from之前的子查询primary最外部的查询simple不包含子查询的简单的查询unionexplain select * from pay where id=1 union select * from pay where id=2结果:使用union进行的联合查询二、table列这一列表示该sql正在访问哪一张表。也可以看出正在访问的衍生表三、tyge列通过Type列,可以直接的看出SQL语句的查询性能,性能从大到小的排列:null>system>const>eq_ref>ref>range>index>ALL一般情况下我们要保证我们的sql类型的性能是range级别。不同的级别的情况:null性能最好的,一般在查询时使用了聚合函数,于是直接从索引树里获取数据,而不用查询表中的记录。explain select min(id) from pay;const在进行查询时,查询的条件,使用了主键列或者唯一索引列的值与常量进行比较,这种性能是非常快的,所以是constsystem是const的特殊情况,一般在衍生表里,直接匹配一条记录,就是systemeq_ref如果顺序一直,按按顺序执行。在进行多表连接查询时。如果查询条件是使用了主键进行比较,那么当前查询类型是eq_refEXPLAIN select * from pay p left join type t on t.id=p.id;ref简单查询:使用普通索引列作为查询条件EXPLAIN select * from pay where name="早餐";复杂查询里:在进行连接查询时,连接查询的条件中使用了本表的联合索引列,因此这种类型的sql就是refrange在索引列上使用了范围查找,性能是ok的。EXPLAIN select * from pay where id<5;index在查询表中的所有的记录,但是所有的记录可以直接从索引树上获取,因此这种sql的查询类型就是index(pay表所有列都有索引)EXPLAIN select name from payall没有走索引,进行全表扫描。全表扫描。就是要从头到尾对表中的数据扫描一遍。这种查询性能是一定要做优化的。4、id列在多个select中,id越大越先执行,如果id相同。上面的先执行。5、possible_keys这一次查询可能使用到的索引(名称)。为什么要设计possiblekey这一列。因为在实际MySQL内部优化器做优化选择时,虽然我们写的sql语句是使用了索引列,但是MySQL内部优化器发现,使用索引列查找的性能并没有比全表扫描的性能要好(可以通过trace工具来查看),于是MySQL内部优化器就选择使用全表扫描。explain select * from pay where name like "早%"结果:可能使用idx_name_repaymentAmount_userName联合索引,实际上没用到。一共有142条记录,使用索引可能也需要扫描142条数据,使用索引效率可能还没有使用全表扫描快。6、key实际sql使用的索引7、rows列该sql语句可能要查询的数据条数8、key_len列键的长度,通过这一列可以让我们知道当前命中了联合索引中的哪几列。name长度是74,也就是当看到key-len是74,表示使用了联合索引中的name列。ken_len计算规则:-字符串1.char(n):n字节长度2.varchar(n):2字节存储字符串长度,如果是utf-8,则长度3n+2-数值类型1.tinyint:1字节2.smallint:2字节3.int:4字节4.bigint:8字节--时间类型1、date:3字节2、timestamp:4字节3、datetime:8字节如果字段允许位null,需要1字节记录是否位null。索引最大长度768字节,当字符串过长时,mysql会做一个类似左前缀索引的处理,讲前半部分的字符提取出来做索引。9、extraextra列提供了额外的信息,是能够帮助我们判断当前sql的是否使用了覆盖索引、文件排序、使用了索引进行查询条件等等的信息。using index覆盖索引:所谓的覆盖索引,指的是当前查询的所有数据字段都是索引列,这就意味着可以直接从索引列中获取数据,而不需要进行查表。使用了覆盖索引explain select repaymentAmount from pay where name ="早餐";using wherewhere的条件没有使用索引列。这种性能不ok的,我们如果条件允许可以给列设置索引,也同样尽可能的使用覆盖索引。explain select * from pay where name like "早%"using index condition查询的列没有完全被索引覆盖,并且where条件中使用普通索引。using temporary会创建临时表来执行,比如在没有索引的列上执行去重操作,就需要临时表来实现。explain select distinct(description) from pay;这种情况可以通过给列加索引进行优化。using filesortMySQL对数据进行排序,都会使用磁盘来完成,可能会借助内存,设计到两个概念:单路排序、双路排序explain select * from pay ORDER BY description;select tables optimized away当直接在索引列上使用聚合函数,意味着不需要操作表。explain select min(id) from pay;编写SQL注意点等值匹配:下面3个都命中:最左前缀法:1、2没命中,4name,age命中。不能在索引列上做计算、函数、类型转换:日志查找如何处理:尽量使用覆盖索引使用不等于(!=或者<>)会导致全表扫描使用is null、is not null会导致全表扫描使用like以通配符开头('%abc..')会导致全表扫描字符串不加单引号会到会导致全表扫描少用or或in,MySQL内部优化器可能不走索引in进行几千条数据查询时,解决方案:在后端通过多线程countDownlatch将几千条数据拆分,通过多个线程每个查询1000条进行结果汇总。范围查询优化Trace工具在执行计划中我们发现有的sql会走索引,有的sql即使明确使用了索引也不会走索引。这是因为mysql的内部优化器任务走索引的性能比不走索引全表扫描的性能要差,因此mysql内部优化器选择了使用全表扫描。依据来自于trace工具的结论。1、开启Traceset session optimizer_trace="enabled=on",end_markers_in_json=on; --开启Traceexplain select * from pay where name>1; --查询 SELECT * FROM information_schema.OPTIMIZER_ ; --获得TRACE信息Trace信息:{ "steps": [ { "join_preparation": { --- 阶段1:准备阶段 "select#": 1, "steps": [ { ----sql变成成下面这种 "expanded_query": "/* select#1 */ select `pay`.`id` AS `id`,`pay`.`name` AS `name`,`pay`.`repaymentAmount` AS `repaymentAmount`,`pay`.`repaymentTime` AS `repaymentTime`,`pay`.`repaymentUser` AS `repaymentUser`,`pay`.`userName` AS `userName`,`pay`.`updateTime` AS `updateTime`,`pay`.`description` AS `description` from `pay` where (`pay`.`name` > 1)" } ] /* steps */ } /* join_preparation */ }, { "join_optimization": { ----阶段2:进入优化阶段 "select#": 1, "steps": [ { "condition_processing": { ---条件处理 "condition": "WHERE", "original_condition": "(`pay`.`name` > 1)", "steps": [ { "transformation": "equality_propagation", "resulting_condition": "(`pay`.`name` > 1)" }, { "transformation": "constant_propagation", "resulting_condition": "(`pay`.`name` > 1)" }, { "transformation": "trivial_condition_removal", "resulting_condition": "(`pay`.`name` > 1)" } ] /* steps */ } /* condition_processing */ }, { "substitute_generated_columns": { } /* substitute_generated_columns */ }, { "table_dependencies": [ -----表依赖详情 { "table": "`pay`", "row_may_be_null": false, "map_bit": 0, "depends_on_map_bits": [ ] /* depends_on_map_bits */ } ] /* table_dependencies */ }, { "ref_optimizer_key_uses": [ ] /* ref_optimizer_key_uses */ }, { "rows_estimation": [ { "table": "`pay`", "range_analysis": { "table_scan": {--表的扫描 "rows": 142, --扫描行数 "cost": 31.5 --花费时间 } /* table_scan */, "potential_range_indexes": [ ----(关键)可能使用的索引 { "index": "PRIMARY", ---主键索引 "usable": false, "cause": "not_applicable" }, { "index": "idx_name_repaymentAmount_userName", ---联合索引 "usable": true, --是否可用 "key_parts": [ "name", "repaymentAmount", "userName", "id" ] /* key_parts */ }, { "index": "idx_id", "usable": false, "cause": "not_applicable" } ] /* potential_range_indexes */, "setup_range_conditions": [ ] /* setup_range_conditions */, "group_index_range": { "chosen": false, "cause": "not_group_by_or_distinct" } /* group_index_range */ } /* range_analysis */ } ] /* rows_estimation */ }, { "considered_execution_plans": [---分析执行计划 { "plan_prefix": [ ] /* plan_prefix */, "table": "`pay`", "best_access_path": { ---最优访问路径 "considered_access_paths": [ --最后选择访问的路径 { "rows_to_scan": 142, --全表扫描行数 "access_type": "scan", --全表扫描 "resulting_rows": 47.329, --结果的行数 "cost": 29.4, ---花费时间 "chosen": true --选择这种方式 } ] /* considered_access_paths */ } /* best_access_path */, "condition_filtering_pct": 100, "rows_for_plan": 47.329, "cost_for_plan": 29.4, "chosen": true } ] /* considered_execution_plans */ }, { "attaching_conditions_to_tables": { "original_condition": "(`pay`.`name` > 1)", "attached_conditions_computation": [ ] /* attached_conditions_computation */, "attached_conditions_summary": [ { "table": "`pay`", "attached": "(`pay`.`name` > 1)" } ] /* attached_conditions_summary */ } /* attaching_conditions_to_tables */ }, { "refine_plan": [ { "table": "`pay`" } ] /* refine_plan */ } ] /* steps */ } /* join_optimization */ }, { "join_explain": { "select#": 1, "steps": [ ] /* steps */ } /* join_explain */ } ] /* steps */ }常见优化方案、1、Order by在Order by中,如果排序会造成文件排序(在磁盘中完成排序,这样的性能会比较差),那么就说明sql没有命中索引,怎么解决?可以使用最左前缀法则,让排序遵循最左前缀法则,避免文件排序。优化手段:如果排序的字段创建了联合索引,那么尽量在业务不冲突的情况下,遵循最左前缀法则来写排序语句。如果文件排序没办法避免,那么尽量想办法使用覆盖索引。all-->index2.Group by优化group by 本质上是先排序后分组,所以排序优化参考Order by优化。3.文件排序的执行原理MySQL在进行文件排序时,会设置一个缓冲区,比较要排序的所有列的数据大小之和,与max_length_for_sort_data(默认是1024个字节)进行比较。如果比系统变量小,那么执行单路排序,反正执行双路排序。单路排序:把所有的数据扔到sort_buffer内存缓冲区中,进行排序,然后结束双路排序:取数据的排序字段和主键字段,在内存缓冲区中排序完成后,将主键字段做一次回表查询,获取完整数据。4、分页查询优化优化方式一:比较少见,因为有curd注意:主键是连续的,如果删除了,获取到的数据条数不对。优化方式二:先覆盖查询,在到小范围里面全表扫描5、join连表查询优化方式一:在join查询中,如果关联字段建立了索引,mysql就会使用nlj算法,去找小表(数据量比较小的表)作为驱动表,先从驱动表中读一行数据,然后拿这一行数据去被驱动表(数据量比较大的表)中做查询。这样的大表和小表是由mysql内部优化器来决定的,跟sql语句中表的书写顺序无关。—NLJ算法(nested loop join:嵌套循环join)方式二:如果没有索引,会创建一个join buffer内存缓冲区,把小表数据存进来(为什么不存大表,因为缓冲区大小限制,及存数据消耗性能的考虑),用内存缓冲区中100行记录去和大表中的1万行记录进行比较,比较的过程依然是在内存中进行的。索引join buffer起到了提高join效率的效果。-BNLJ算法(block nested loop join:块嵌套循环join)结论:如果使用join查询,那么join的两个表的关联字段一定要创建索引,而且字段的长度类型一定是要一致的(在建表时就要做好),否则索引会失效,会使用BNLJ算法,全表扫描的效果。6、in和exits优化在sql中如果A表是大表,B表是小表,那么使用in会更加合适。反之应该使用exists。in:前提B数据量<A数据量select * from A where id in (select id from B);exists: B的数据量>A的数据量select * from A where exists (select id from B where B.id=A.id);select id from B where B.id=A.id ---会返回true/false,true才查询B7、count优化对于count的优化应该是架构层面的优化,因为count的统计是在一个产品会经常出现,而且每个用户访问,所以对于访问频率过高的数据建议维护在缓存中。锁的定义和分类1、锁的定义锁是用来解决多个任务(线程、进程)在并发访问同一共享资源时带来的数据安全问题。虽然使用锁解决了数据安全问题,但是会带来性能的影响,频繁使用锁的程序的性能是必然很差的。对于数据管理软件MySQL来说,必然会到任务的并发访问。那么MySQL是怎么样在数据安全和性能上做权衡的呢?——MVCC设计思2、锁的分类1、)从性能上划分:乐观锁和悲观锁悲观锁:悲观的认为当前的并发是非常严重的,所以在任何时候操作都是互斥。保证了线程的安全,但牺牲了并发性。乐观锁:乐观的认为当前的并发并不严重,因此对于读的情况,大家都可以进行,但是对于写的情况,再进行上锁。以CAS自旋锁在某种性能是ok的,但是频繁自旋会消耗很大的资源。2、)从数据的操作细粒度上划分:表锁和行锁表锁:对整张表上锁行锁:对表中的某一行上锁。3、)从数据库的操作类型上划分:读锁和写锁,这2中锁都是悲观锁。读锁(共享锁):对于同一行数据进行”读“来说,是可以同时进行但是写不行。写锁(拍他锁):在上了写锁之后,及释放写锁之前,在整个过程中是不能进行任何的其他并发操作(其他任务的读和写是都不能进行的)。表锁:对整张表进行上锁。MyISAM存储引擎是天然支持表锁的,也就是说在MyISAM的存储引擎的表中如果出现并发的情况,将会出现表锁的效果。MyISAM不支持事务。读锁:其他任务可以进行读,但是不能进行写写锁:其他任务不能进行读和写。行锁:MyISAM只支持表锁,但不支持行锁,InnoDB可以支持行锁。在并发事务里,每个事务的增删改的操作相当于是上了行锁。MVCC设计思想MySQL为了权衡数据安全和性能,使用了MVCC多版本并发控制的设计。MVCC,全称Multi-Version Concurrency Control,即多版本并发控制。MVCC是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存。1、事务的特性原子性:一个事务是一个最小的操作单位(原子),多条sql语句在一个事务中要么同时成功,要么同时失败。一致性:事务提交之前和回滚之后的数据是一致的。持久性:事务一旦提交,对数据的影响是持久的。隔离性:多个事务在并发访问下,提供了一套隔离机制,不同的隔离级别会有不同的并发效果。2、事务的隔离级别幻读:开启2个事务(隔离级别位可重复读),2个事务进行查询,第一个事务插入了一条记录,然后提交。第二个事务,再次插入相同id记录时,提示id重复,查询却看不到第一个事务插入的记录。这种现象就是幻读(虚度).解决办法,将隔离级别设置成Serializable串行化,但是却西能了性能。另一种解决方案:通过上行锁来解决虚读问题。MVCC思想解读:MySQL在读和写的操作中,对读的性能做了并发性的保障,让所有的读都是快照读,对于写的时候,进行版本控制,如果真实数据的版本比快照版本要新,那么写之前就要进行版本(快照)更新,这样就可以既能够提高读的并发性,又能够保证写的数据安全。死锁和间歇锁1、死锁所谓的死锁,就是开启的锁没有办法关闭,导致资源的访问因为无法获得锁而处于阻塞状态。演示:事务A和事物B相互持有对方需要的锁而不释放,造成死锁的情况。2、间隙锁行锁只能对某一行上锁,如果相对某一个范围上锁,就可以使用间隙锁。间隙锁给的条件where id>13 and id<19,会对13和19所处的间隙进行上锁。
-
-
Docker安装MySQL 安装前提,已经搭建好Docker环境,关于docker安装可参考我另一篇文章《Docker安装》一、Docker安装MySQL拉取Docker镜像docker pull mysql:5.7运行MySQL容器,参数说明见-说明1docker run -p 3306:3306 --name mysql \ -v /mydata/mysql/log:/var/log/mysql \ -v /mydata/mysql/data:/var/lib/mysql \ -v /mydata/mysql/conf:/etc/mysql \ -e MYSQL_ROOT_PASSWORD=密码 \ -d mysql:5.7二、MySQL配置修改MySQL配置文件,my.cnf内容见-说明2vi /mydata/mysql/conf/my.cnf容器的mysql 命令行工具连接docker exec -it mysql mysql -uroot -p注意:会提示输入密码,也就是上面2运行容器时配置的密码设置root 远程访问grant all privileges on *.* to 'root'@'%' identified by '密码' with grant option;刷新MySQL配置flush privileges;重启MySQL容器docker restart mysql设置启动Docker是启动MySQL容器docker update --restart=always mysql说明1:-p 3306:3306:将容器的3306 端口映射到主机的3306 端口-v /mydata/mysql/conf:/etc/mysql:将配置文件夹挂载到主机-v /mydata/mysql/log:/var/log/mysql:将日志文件夹挂载到主机-v /mydata/mysql/data:/var/lib/mysql/:将配置文件夹挂载到主机-e MYSQL_ROOT_PASSWORD=密码:root 用户密码注意:log\data\conf几个文件夹及路径不用手动新建,运行时会自动创建。说明2:my.cnf文件内容:[client] default-character-set=utf8 [mysql] default-character-set=utf8 [mysqld] init_connect='SET collation_connection=utf8_unicode_ci' init_connect='SET NAMES utf8' character-set-server=utf8 collation-server=utf8_unicode_ci skip-character-set-client-handshake skip-name-resolve说明:skip-name-resolve:跳过域名解析default-character-set=utf8:设置编码
![[ERR] 1067 - Invalid default value for 'created_date_' [ERR]](https://www.yanxizhu.com/usr/themes/Joe/assets/thumb/36.jpg)