搜索到
10
篇与
的结果
-
![[ERR] 1067 - Invalid default value for 'created_date_' [ERR]](https://minio.yanxizhu.com/blog/lazyload.jpg)
-
Nacos持久化MySQL问题-解决方案 Nacos持久化MySQL问题-解决方案一、说明环境说明:MySQL:CentOS环境通过Docker部署的MySQL5.7Nacos:2.0.3原始配置:### If use MySQL as datasource: # spring.datasource.platform=mysql ### Count of DB: # db.num=1 ### Connect URL of DB: # db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC # db.user.0=nacos # db.password.0=nacos二、问题启动nacos持久化MySQL报错:/usr/local/java/jdk-11.0.10/bin/java -Xms512m -Xmx512m -Xmn256m -Dnacos.standalone=true -Dnacos.member.list= -Xlog:gc*:file=/usr/local/nacos/logs/nacos_gc.log:time,tags:filecount=10,filesize=102400 -Dloader.path=/usr/local/nacos/plugins/health,/usr/local/nacos/plugins/cmdb -Dnacos.home=/usr/local/nacos -jar /usr/local/nacos/target/nacos-server.jar --spring.config.additional-location=file:/usr/local/nacos/conf/ --logging.config=/usr/local/nacos/conf/nacos-logback.xml --server.max-http-header-size=524288 ,--. ,--.'| ,--,: : | Nacos 2.0.3 ,`--.'`| ' : ,---. Running in stand alone mode, All function modules | : : | | ' ,'\ .--.--. Port: 8848 : | \ | : ,--.--. ,---. / / | / / ' Pid: 3180 | : ' '; | / \ / \. ; ,. :| : /`./ Console: http://192.168.56.10:8848/nacos/index.html ' ' ;. ;.--. .-. | / / '' | |: :| : ;_ | | | \ | \__\/: . .. ' / ' | .; : \ \ `. https://nacos.io ' : | ; .' ," .--.; |' ; :__| : | `----. \ | | '`--' / / ,. |' | '.'|\ \ / / /`--' / ' : | ; : .' \ : : `----' '--'. / ; |.' | , .-./\ \ / `--'---' '---' `--`---' `----' 2022-10-26 12:12:21,501 INFO Bean 'org.springframework.security.access.expression.method.DefaultMethodSecurityExpressionHandler@7c8f9c2e' of type [org.springframework.security.access.expression.method.DefaultMethodSecurityExpressionHandler] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying) 2022-10-26 12:12:21,506 INFO Bean 'methodSecurityMetadataSource' of type [org.springframework.security.access.method.DelegatingMethodSecurityMetadataSource] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying) 2022-10-26 12:12:21,880 INFO Tomcat initialized with port(s): 8848 (http) 2022-10-26 12:12:22,303 INFO Root WebApplicationContext: initialization completed in 4845 ms 2022-10-26 12:12:34,613 WARN Exception encountered during context initialization - cancelling refresh attempt: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'memoryMonitor' defined in URL [jar:file:/usr/local/nacos/target/nacos-server.jar!/BOOT-INF/lib/nacos-config-2.0.3.jar!/com/alibaba/nacos/config/server/monitor/MemoryMonitor.class]: Unsatisfied dependency expressed through constructor parameter 0; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'asyncNotifyService': Unsatisfied dependency expressed through field 'dumpService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'externalDumpService': Invocation of init method failed; nested exception is ErrCode:500, ErrMsg:Nacos Server did not start because dumpservice bean construction failure : No DataSource set 2022-10-26 12:12:34,644 INFO Nacos Log files: /usr/local/nacos/logs 2022-10-26 12:12:34,644 INFO Nacos Log files: /usr/local/nacos/conf 2022-10-26 12:12:34,644 INFO Nacos Log files: /usr/local/nacos/data 2022-10-26 12:12:34,644 ERROR Startup errors : org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'memoryMonitor' defined in URL [jar:file:/usr/local/nacos/target/nacos-server.jar!/BOOT-INF/lib/nacos-config-2.0.3.jar!/com/alibaba/nacos/config/server/monitor/MemoryMonitor.class]: Unsatisfied dependency expressed through constructor parameter 0; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'asyncNotifyService': Unsatisfied dependency expressed through field 'dumpService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'externalDumpService': Invocation of init method failed; nested exception is ErrCode:500, ErrMsg:Nacos Server did not start because dumpservice bean construction failure : No DataSource set at org.springframework.beans.factory.support.ConstructorResolver.createArgumentArray(ConstructorResolver.java:769) at org.springframework.beans.factory.support.ConstructorResolver.autowireConstructor(ConstructorResolver.java:218) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.autowireConstructor(AbstractAutowireCapableBeanFactory.java:1338) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBeanInstance(AbstractAutowireCapableBeanFactory.java:1185) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:554) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:514) at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:321) at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:319) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:199) at org.springframework.beans.factory.support.DefaultListableBeanFactory.preInstantiateSingletons(DefaultListableBeanFactory.java:866) at org.springframework.context.support.AbstractApplicationContext.finishBeanFactoryInitialization(AbstractApplicationContext.java:878) at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:550) at org.springframework.boot.web.servlet.context.ServletWebServerApplicationContext.refresh(ServletWebServerApplicationContext.java:141) at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:744) at org.springframework.boot.SpringApplication.refreshContext(SpringApplication.java:391) at org.springframework.boot.SpringApplication.run(SpringApplication.java:312) at org.springframework.boot.SpringApplication.run(SpringApplication.java:1215) at org.springframework.boot.SpringApplication.run(SpringApplication.java:1204) at com.alibaba.nacos.Nacos.main(Nacos.java:35) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.base/java.lang.reflect.Method.invoke(Method.java:566) at org.springframework.boot.loader.MainMethodRunner.run(MainMethodRunner.java:49) at org.springframework.boot.loader.Launcher.launch(Launcher.java:108) at org.springframework.boot.loader.Launcher.launch(Launcher.java:58) at org.springframework.boot.loader.PropertiesLauncher.main(PropertiesLauncher.java:467) Caused by: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'asyncNotifyService': Unsatisfied dependency expressed through field 'dumpService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'externalDumpService': Invocation of init method failed; nested exception is ErrCode:500, ErrMsg:Nacos Server did not start because dumpservice bean construction failure : No DataSource set at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement.inject(AutowiredAnnotationBeanPostProcessor.java:598) at org.springframework.beans.factory.annotation.InjectionMetadata.inject(InjectionMetadata.java:90) at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor.postProcessProperties(AutowiredAnnotationBeanPostProcessor.java:376) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.populateBean(AbstractAutowireCapableBeanFactory.java:1402) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:591) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:514) at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:321) at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:319) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:199) at org.springframework.beans.factory.config.DependencyDescriptor.resolveCandidate(DependencyDescriptor.java:277) at org.springframework.beans.factory.support.DefaultListableBeanFactory.doResolveDependency(DefaultListableBeanFactory.java:1276) at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveDependency(DefaultListableBeanFactory.java:1196) at org.springframework.beans.factory.support.ConstructorResolver.resolveAutowiredArgument(ConstructorResolver.java:857) at org.springframework.beans.factory.support.ConstructorResolver.createArgumentArray(ConstructorResolver.java:760) ... 27 common frames omitted Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'externalDumpService': Invocation of init method failed; nested exception is ErrCode:500, ErrMsg:Nacos Server did not start because dumpservice bean construction failure : No DataSource set at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor.postProcessBeforeInitialization(InitDestroyAnnotationBeanPostProcessor.java:139) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsBeforeInitialization(AbstractAutowireCapableBeanFactory.java:413) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1761) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:592) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:514) at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:321) at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:319) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:199) at org.springframework.beans.factory.config.DependencyDescriptor.resolveCandidate(DependencyDescriptor.java:277) at org.springframework.beans.factory.support.DefaultListableBeanFactory.doResolveDependency(DefaultListableBeanFactory.java:1276) at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveDependency(DefaultListableBeanFactory.java:1196) at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement.inject(AutowiredAnnotationBeanPostProcessor.java:595) ... 41 common frames omitted Caused by: com.alibaba.nacos.api.exception.NacosException: Nacos Server did not start because dumpservice bean construction failure : No DataSource set at com.alibaba.nacos.config.server.service.dump.DumpService.dumpOperate(DumpService.java:236) at com.alibaba.nacos.config.server.service.dump.ExternalDumpService.init(ExternalDumpService.java:52) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.base/java.lang.reflect.Method.invoke(Method.java:566) at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor$LifecycleElement.invoke(InitDestroyAnnotationBeanPostProcessor.java:363) at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor$LifecycleMetadata.invokeInitMethods(InitDestroyAnnotationBeanPostProcessor.java:307) at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor.postProcessBeforeInitialization(InitDestroyAnnotationBeanPostProcessor.java:136) ... 53 common frames omitted Caused by: java.lang.IllegalStateException: No DataSource set at org.springframework.util.Assert.state(Assert.java:73) at org.springframework.jdbc.support.JdbcAccessor.obtainDataSource(JdbcAccessor.java:77) at org.springframework.jdbc.core.JdbcTemplate.execute(JdbcTemplate.java:371) at org.springframework.jdbc.core.JdbcTemplate.query(JdbcTemplate.java:452) at org.springframework.jdbc.core.JdbcTemplate.query(JdbcTemplate.java:462) at org.springframework.jdbc.core.JdbcTemplate.queryForObject(JdbcTemplate.java:473) at org.springframework.jdbc.core.JdbcTemplate.queryForObject(JdbcTemplate.java:480) at com.alibaba.nacos.config.server.service.repository.extrnal.ExternalStoragePersistServiceImpl.findConfigMaxId(ExternalStoragePersistServiceImpl.java:658) at com.alibaba.nacos.config.server.service.dump.processor.DumpAllProcessor.process(DumpAllProcessor.java:51) at com.alibaba.nacos.config.server.service.dump.DumpService.dumpConfigInfo(DumpService.java:293) at com.alibaba.nacos.config.server.service.dump.DumpService.dumpOperate(DumpService.java:205) ... 61 common frames omitted 2022-10-26 12:12:36,322 WARN [WatchFileCenter] start close 2022-10-26 12:12:36,322 WARN [WatchFileCenter] start to shutdown this watcher which is watch : /usr/local/nacos/data/loader 2022-10-26 12:12:36,322 WARN [WatchFileCenter] start to shutdown this watcher which is watch : /usr/local/nacos/conf 2022-10-26 12:12:36,322 WARN [WatchFileCenter] start to shutdown this watcher which is watch : /usr/local/nacos/data/tps 2022-10-26 12:12:36,322 WARN [WatchFileCenter] already closed 2022-10-26 12:12:36,322 WARN [NotifyCenter] Start destroying Publisher 2022-10-26 12:12:36,322 WARN [NotifyCenter] Destruction of the end 2022-10-26 12:12:36,323 ERROR Nacos failed to start, please see /usr/local/nacos/logs/nacos.log for more details. 2022-10-26 12:12:36,345 INFO Error starting ApplicationContext. To display the conditions report re-run your application with 'debug' enabled. 2022-10-26 12:12:36,350 ERROR Application run failed org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'memoryMonitor' defined in URL [jar:file:/usr/local/nacos/target/nacos-server.jar!/BOOT-INF/lib/nacos-config-2.0.3.jar!/com/alibaba/nacos/config/server/monitor/MemoryMonitor.class]: Unsatisfied dependency expressed through constructor parameter 0; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'asyncNotifyService': Unsatisfied dependency expressed through field 'dumpService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'externalDumpService': Invocation of init method failed; nested exception is ErrCode:500, ErrMsg:Nacos Server did not start because dumpservice bean construction failure : No DataSource set at org.springframework.beans.factory.support.ConstructorResolver.createArgumentArray(ConstructorResolver.java:769) at org.springframework.beans.factory.support.ConstructorResolver.autowireConstructor(ConstructorResolver.java:218) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.autowireConstructor(AbstractAutowireCapableBeanFactory.java:1338) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBeanInstance(AbstractAutowireCapableBeanFactory.java:1185) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:554) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:514) at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:321) at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:319) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:199) at org.springframework.beans.factory.support.DefaultListableBeanFactory.preInstantiateSingletons(DefaultListableBeanFactory.java:866) at org.springframework.context.support.AbstractApplicationContext.finishBeanFactoryInitialization(AbstractApplicationContext.java:878) at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:550) at org.springframework.boot.web.servlet.context.ServletWebServerApplicationContext.refresh(ServletWebServerApplicationContext.java:141) at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:744) at org.springframework.boot.SpringApplication.refreshContext(SpringApplication.java:391) at org.springframework.boot.SpringApplication.run(SpringApplication.java:312) at org.springframework.boot.SpringApplication.run(SpringApplication.java:1215) at org.springframework.boot.SpringApplication.run(SpringApplication.java:1204) at com.alibaba.nacos.Nacos.main(Nacos.java:35) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.base/java.lang.reflect.Method.invoke(Method.java:566) at org.springframework.boot.loader.MainMethodRunner.run(MainMethodRunner.java:49) at org.springframework.boot.loader.Launcher.launch(Launcher.java:108) at org.springframework.boot.loader.Launcher.launch(Launcher.java:58) at org.springframework.boot.loader.PropertiesLauncher.main(PropertiesLauncher.java:467) Caused by: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'asyncNotifyService': Unsatisfied dependency expressed through field 'dumpService'; nested exception is org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'externalDumpService': Invocation of init method failed; nested exception is ErrCode:500, ErrMsg:Nacos Server did not start because dumpservice bean construction failure : No DataSource set at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement.inject(AutowiredAnnotationBeanPostProcessor.java:598) at org.springframework.beans.factory.annotation.InjectionMetadata.inject(InjectionMetadata.java:90) at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor.postProcessProperties(AutowiredAnnotationBeanPostProcessor.java:376) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.populateBean(AbstractAutowireCapableBeanFactory.java:1402) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:591) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:514) at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:321) at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:319) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:199) at org.springframework.beans.factory.config.DependencyDescriptor.resolveCandidate(DependencyDescriptor.java:277) at org.springframework.beans.factory.support.DefaultListableBeanFactory.doResolveDependency(DefaultListableBeanFactory.java:1276) at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveDependency(DefaultListableBeanFactory.java:1196) at org.springframework.beans.factory.support.ConstructorResolver.resolveAutowiredArgument(ConstructorResolver.java:857) at org.springframework.beans.factory.support.ConstructorResolver.createArgumentArray(ConstructorResolver.java:760) ... 27 common frames omitted Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'externalDumpService': Invocation of init method failed; nested exception is ErrCode:500, ErrMsg:Nacos Server did not start because dumpservice bean construction failure : No DataSource set at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor.postProcessBeforeInitialization(InitDestroyAnnotationBeanPostProcessor.java:139) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsBeforeInitialization(AbstractAutowireCapableBeanFactory.java:413) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1761) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:592) at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:514) at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:321) at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:319) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:199) at org.springframework.beans.factory.config.DependencyDescriptor.resolveCandidate(DependencyDescriptor.java:277) at org.springframework.beans.factory.support.DefaultListableBeanFactory.doResolveDependency(DefaultListableBeanFactory.java:1276) at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveDependency(DefaultListableBeanFactory.java:1196) at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement.inject(AutowiredAnnotationBeanPostProcessor.java:595) ... 41 common frames omitted Caused by: com.alibaba.nacos.api.exception.NacosException: Nacos Server did not start because dumpservice bean construction failure : No DataSource set at com.alibaba.nacos.config.server.service.dump.DumpService.dumpOperate(DumpService.java:236) at com.alibaba.nacos.config.server.service.dump.ExternalDumpService.init(ExternalDumpService.java:52) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.base/java.lang.reflect.Method.invoke(Method.java:566) at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor$LifecycleElement.invoke(InitDestroyAnnotationBeanPostProcessor.java:363) at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor$LifecycleMetadata.invokeInitMethods(InitDestroyAnnotationBeanPostProcessor.java:307) at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor.postProcessBeforeInitialization(InitDestroyAnnotationBeanPostProcessor.java:136) ... 53 common frames omitted Caused by: java.lang.IllegalStateException: No DataSource set at org.springframework.util.Assert.state(Assert.java:73) at org.springframework.jdbc.support.JdbcAccessor.obtainDataSource(JdbcAccessor.java:77) at org.springframework.jdbc.core.JdbcTemplate.execute(JdbcTemplate.java:371) at org.springframework.jdbc.core.JdbcTemplate.query(JdbcTemplate.java:452) at org.springframework.jdbc.core.JdbcTemplate.query(JdbcTemplate.java:462) at org.springframework.jdbc.core.JdbcTemplate.queryForObject(JdbcTemplate.java:473) at org.springframework.jdbc.core.JdbcTemplate.queryForObject(JdbcTemplate.java:480) at com.alibaba.nacos.config.server.service.repository.extrnal.ExternalStoragePersistServiceImpl.findConfigMaxId(ExternalStoragePersistServiceImpl.java:658) at com.alibaba.nacos.config.server.service.dump.processor.DumpAllProcessor.process(DumpAllProcessor.java:51) at com.alibaba.nacos.config.server.service.dump.DumpService.dumpConfigInfo(DumpService.java:293) at com.alibaba.nacos.config.server.service.dump.DumpService.dumpOperate(DumpService.java:205) ... 61 common frames omitted三、参考方案Google到许多解决方案:主要针对application.properties配置文件,数据库配置部分。### If use MySQL as datasource: spring.datasource.platform=mysql ### Count of DB: db.num=1 ### Connect URL of DB: db.url.0=jdbc:mysql://127.0.0.1:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC db.user.0=root db.password.0=root1、检查MySQL账号、密码、IP、端口是否正确。2、数据库连接是否有加时区,serverTimezone=Asia/Shanghai3、数据库版本8.0,需要在nacos下创建plugins/mysql目录,并将mysql-connector-java-8.0.23.jar放入。4、密码有特殊字符的,加单引号。5、查看防火墙端口是否放开或关闭。四、最终解决方案本地问题总结:1、Navicat连接数据库时,连接到了本地,未连接到CentOS系统。因此执行nacos脚本数据库肯定找不到。2、自己创建的数据库为nacos,而实际nacos-mysql.sql 脚本中数据库为nacos_config,因此也找不到。3、application.properties中配置的数据库名称和要和CentOS中创建的数据库名要一样,编码最好也一致。最后启动成功。/usr/local/java/jdk-11.0.10/bin/java -Xms512m -Xmx512m -Xmn256m -Dnacos.standalone=true -Dnacos.member.list= -Xlog:gc*:file=/usr/local/nacos/logs/nacos_gc.log:time,tags:filecount=10,filesize=102400 -Dloader.path=/usr/local/nacos/plugins/health,/usr/local/nacos/plugins/cmdb -Dnacos.home=/usr/local/nacos -jar /usr/local/nacos/target/nacos-server.jar --spring.config.additional-location=file:/usr/local/nacos/conf/ --logging.config=/usr/local/nacos/conf/nacos-logback.xml --server.max-http-header-size=524288 ,--. ,--.'| ,--,: : | Nacos 2.0.3 ,`--.'`| ' : ,---. Running in stand alone mode, All function modules | : : | | ' ,'\ .--.--. Port: 8848 : | \ | : ,--.--. ,---. / / | / / ' Pid: 3408 | : ' '; | / \ / \. ; ,. :| : /`./ Console: http://192.168.56.10:8848/nacos/index.html ' ' ;. ;.--. .-. | / / '' | |: :| : ;_ | | | \ | \__\/: . .. ' / ' | .; : \ \ `. https://nacos.io ' : | ; .' ," .--.; |' ; :__| : | `----. \ | | '`--' / / ,. |' | '.'|\ \ / / /`--' / ' : | ; : .' \ : : `----' '--'. / ; |.' | , .-./\ \ / `--'---' '---' `--`---' `----' 2022-10-26 12:16:14,753 INFO Bean 'org.springframework.security.access.expression.method.DefaultMethodSecurityExpressionHandler@8a2a6a' of type [org.springframework.security.access.expression.method.DefaultMethodSecurityExpressionHandler] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying) 2022-10-26 12:16:14,763 INFO Bean 'methodSecurityMetadataSource' of type [org.springframework.security.access.method.DelegatingMethodSecurityMetadataSource] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying) 2022-10-26 12:16:15,308 INFO Tomcat initialized with port(s): 8848 (http) 2022-10-26 12:16:15,818 INFO Root WebApplicationContext: initialization completed in 5099 ms WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by com.alipay.sofa.jraft.util.internal.UnsafeUtil (jar:file:/usr/local/nacos/target/nacos-server.jar!/BOOT-INF/lib/jraft-core-1.3.5.jar!/) to field java.nio.Buffer.address WARNING: Please consider reporting this to the maintainers of com.alipay.sofa.jraft.util.internal.UnsafeUtil WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release 2022-10-26 12:16:22,286 INFO Initializing ExecutorService 'applicationTaskExecutor' 2022-10-26 12:16:22,526 INFO Adding welcome page: class path resource [static/index.html] 2022-10-26 12:16:24,101 INFO Creating filter chain: Ant [pattern='/**'], [] 2022-10-26 12:16:24,133 INFO Creating filter chain: any request, [org.springframework.security.web.context.request.async.WebAsyncManagerIntegrationFilter@3313463c, org.springframework.security.web.context.SecurityContextPersistenceFilter@1bfa5a13, org.springframework.security.web.header.HeaderWriterFilter@6eed46e9, org.springframework.security.web.csrf.CsrfFilter@f849027, org.springframework.security.web.authentication.logout.LogoutFilter@76af34b5, org.springframework.security.web.savedrequest.RequestCacheAwareFilter@1da75dde, org.springframework.security.web.servletapi.SecurityContextHolderAwareRequestFilter@595fed99, org.springframework.security.web.authentication.AnonymousAuthenticationFilter@9c0d0bd, org.springframework.security.web.session.SessionManagementFilter@690df641, org.springframework.security.web.access.ExceptionTranslationFilter@6ce9771c] 2022-10-26 12:16:24,276 INFO Initializing ExecutorService 'taskScheduler' 2022-10-26 12:16:24,342 INFO Exposing 16 endpoint(s) beneath base path '/actuator' 2022-10-26 12:16:24,621 INFO Tomcat started on port(s): 8848 (http) with context path '/nacos' 2022-10-26 12:16:24,696 INFO Nacos started successfully in stand alone mode. use embedded storage
-
Jenkins容器docker部署springboot项目-问题记录 Jenkins容器docker部署springboot项目-问题记录一、docker容器内不能使用vim解决方案:以root进入容器内docker exec -it -user root jenkins /bin/bash更新软件包apt-get update升级过程可能非常慢,因为是从海外站点拉取镜像,所以我们可以配置一个国内的镜像源,加速镜像拉取更新。备份原文件mv /etc/apt/sources.list /etc/apt/sources.list.bak查看容器中Debian版本cat /etc/issue修改配置sources.list文件根据自己版本修改成对应内容,修改内容参考阿里镜像https://developer.aliyun.com/mirror/debian我容器Debian为11.x版本,修改内容为:cat >/etc/apt/sources.list <<EOF deb http://mirrors.aliyun.com/debian/ bullseye main non-free contrib deb-src http://mirrors.aliyun.com/debian/ bullseye main non-free contrib deb http://mirrors.aliyun.com/debian-security/ bullseye-security main deb-src http://mirrors.aliyun.com/debian-security/ bullseye-security main deb http://mirrors.aliyun.com/debian/ bullseye-updates main non-free contrib deb-src http://mirrors.aliyun.com/debian/ bullseye-updates main non-free contrib deb http://mirrors.aliyun.com/debian/ bullseye-backports main non-free contrib deb-src http://mirrors.aliyun.com/debian/ bullseye-backports main non-free contrib EOF重新执行apt-get update安装vimapt-get install -y vim安装rpmapt-get install rpm -y二、docker容器内vim不能粘贴内容vim右键进入visual模式无法粘贴解决方案vim /usr/share/vim/vim80/defaults.vim修改内容:第70行,在mouse=a的=前面加个-,修改后如下:if has('mouse') set mouse-=a endif三、docker容器内环境配置修改环境变量配置vi /etc/profile新增jdk、mavn环境变量配置# java环境变量 export JAVA_HOME=/jdk/jdk-11.0.10 export JRE_HOME=$JAVA_HOME/jre export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=./:JAVA_HOME/lib:$JRE_HOME/lib # maven环境变量 export M2_HOME=/maven/apache-maven-3.8.5 export PATH=$PATH:$JAVA_HOME/bin:$M2_HOME/bin重新加载环境变量source /etc/profile检验是否配置成功java -version mvn -v
-
iptables failed: iptables --wait -t nat -A DOCKER -p tcp -d 0/0 --dport 10241 -j DNAT --to-destination 172.17.0.5:50000 ! -i docker0: iptables: No chain/target/match by that name. iptables failed: iptables --wait -t nat -A DOCKER -p tcp -d 0/0 --dport 10241 -j DNAT --to-destination 172.17.0.5:50000 ! -i docker0: iptables: No chain/target/match by that name.docker启动Jenkins报错:iptables failed: iptables --wait -t nat -A DOCKER -p tcp -d 0/0 --dport 10241 -j DNAT --to-destination 172.17.0.5:50000 ! -i docker0: iptables: No chain/target/match by that name.解决办法:重启dockersystemctl restart docker
-
-
Springboot同一Server类方法调用事务解决方案 Springboot同一Server类方法调用事务解决方案1、引入springboot-aop start<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> </dependency>主要是使用里面的动态代理 <dependency> <groupId>org.aspectj</groupId> <artifactId>aspectjweaver</artifactId> <version>1.9.7</version> <scope>compile</scope> </dependency>2、开启动态代理@EnableAspectJAutoProxy(exposeProxy = true) @EnableDiscoveryClient @SpringBootApplication public class FamilyBookingApplication { public static void main(String[] args) { SpringApplication.run(FamilyBookingApplication.class, args); } }@EnableAspectJAutoProxy(exposeProxy = true):开启aspectj动态代理功能。以后所有的动态代理都是aspectj对象暴露代理对象。3、本类互调用代理对象调用@Service("userService") public class UserServiceImpl implements userService { @Transactional public void a(){ UserService userService = (UserService)AopContext.currentProxy(); userService.b(); userService.c(); } @Transactional public void b(){ } @Transactional public void c(){ } }
-
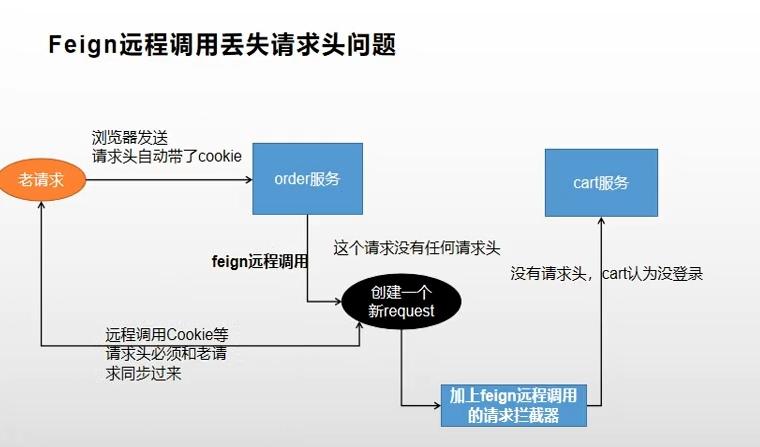
Feign远程调用丢失请求头问题 openFeign远程调用丢失请求头feign在远程调用之前要构造请求,调用会经过很多拦截器。丢失请求头原因,是远程调用重新构建了request请求,新的request没有请求头headr。解决方案:定义一个feign的拦截器先来看一下feign远程调用类SynchronousMethodHandler// // Source code recreated from a .class file by IntelliJ IDEA // (powered by FernFlower decompiler) // package feign; import feign.InvocationHandlerFactory.MethodHandler; import feign.Logger.Level; import feign.Request.Options; import feign.codec.Decoder; import feign.codec.ErrorDecoder; import java.io.IOException; import java.util.Iterator; import java.util.List; import java.util.concurrent.CompletableFuture; import java.util.concurrent.CompletionException; import java.util.concurrent.TimeUnit; import java.util.stream.Stream; final class SynchronousMethodHandler implements MethodHandler { private static final long MAX_RESPONSE_BUFFER_SIZE = 8192L; private final MethodMetadata metadata; private final Target<?> target; private final Client client; private final Retryer retryer; private final List<RequestInterceptor> requestInterceptors; private final Logger logger; private final Level logLevel; private final feign.RequestTemplate.Factory buildTemplateFromArgs; private final Options options; private final ExceptionPropagationPolicy propagationPolicy; private final Decoder decoder; private final AsyncResponseHandler asyncResponseHandler; private SynchronousMethodHandler(Target<?> target, Client client, Retryer retryer, List<RequestInterceptor> requestInterceptors, Logger logger, Level logLevel, MethodMetadata metadata, feign.RequestTemplate.Factory buildTemplateFromArgs, Options options, Decoder decoder, ErrorDecoder errorDecoder, boolean decode404, boolean closeAfterDecode, ExceptionPropagationPolicy propagationPolicy, boolean forceDecoding) { this.target = (Target)Util.checkNotNull(target, "target", new Object[0]); this.client = (Client)Util.checkNotNull(client, "client for %s", new Object[]{target}); this.retryer = (Retryer)Util.checkNotNull(retryer, "retryer for %s", new Object[]{target}); this.requestInterceptors = (List)Util.checkNotNull(requestInterceptors, "requestInterceptors for %s", new Object[]{target}); this.logger = (Logger)Util.checkNotNull(logger, "logger for %s", new Object[]{target}); this.logLevel = (Level)Util.checkNotNull(logLevel, "logLevel for %s", new Object[]{target}); this.metadata = (MethodMetadata)Util.checkNotNull(metadata, "metadata for %s", new Object[]{target}); this.buildTemplateFromArgs = (feign.RequestTemplate.Factory)Util.checkNotNull(buildTemplateFromArgs, "metadata for %s", new Object[]{target}); this.options = (Options)Util.checkNotNull(options, "options for %s", new Object[]{target}); this.propagationPolicy = propagationPolicy; if (forceDecoding) { this.decoder = decoder; this.asyncResponseHandler = null; } else { this.decoder = null; this.asyncResponseHandler = new AsyncResponseHandler(logLevel, logger, decoder, errorDecoder, decode404, closeAfterDecode); } } public Object invoke(Object[] argv) throws Throwable { RequestTemplate template = this.buildTemplateFromArgs.create(argv); Options options = this.findOptions(argv); Retryer retryer = this.retryer.clone(); while(true) { try { return this.executeAndDecode(template, options); } catch (RetryableException var9) { RetryableException e = var9; try { retryer.continueOrPropagate(e); } catch (RetryableException var8) { Throwable cause = var8.getCause(); if (this.propagationPolicy == ExceptionPropagationPolicy.UNWRAP && cause != null) { throw cause; } throw var8; } if (this.logLevel != Level.NONE) { this.logger.logRetry(this.metadata.configKey(), this.logLevel); } } } } Object executeAndDecode(RequestTemplate template, Options options) throws Throwable { Request request = this.targetRequest(template); if (this.logLevel != Level.NONE) { this.logger.logRequest(this.metadata.configKey(), this.logLevel, request); } long start = System.nanoTime(); Response response; try { response = this.client.execute(request, options); response = response.toBuilder().request(request).requestTemplate(template).build(); } catch (IOException var12) { if (this.logLevel != Level.NONE) { this.logger.logIOException(this.metadata.configKey(), this.logLevel, var12, this.elapsedTime(start)); } throw FeignException.errorExecuting(request, var12); } long elapsedTime = TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - start); if (this.decoder != null) { return this.decoder.decode(response, this.metadata.returnType()); } else { CompletableFuture<Object> resultFuture = new CompletableFuture(); this.asyncResponseHandler.handleResponse(resultFuture, this.metadata.configKey(), response, this.metadata.returnType(), elapsedTime); try { if (!resultFuture.isDone()) { throw new IllegalStateException("Response handling not done"); } else { return resultFuture.join(); } } catch (CompletionException var13) { Throwable cause = var13.getCause(); if (cause != null) { throw cause; } else { throw var13; } } } } long elapsedTime(long start) { return TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - start); } Request targetRequest(RequestTemplate template) { Iterator var2 = this.requestInterceptors.iterator(); while(var2.hasNext()) { RequestInterceptor interceptor = (RequestInterceptor)var2.next(); interceptor.apply(template); } return this.target.apply(template); } Options findOptions(Object[] argv) { if (argv != null && argv.length != 0) { Stream var10000 = Stream.of(argv); Options.class.getClass(); var10000 = var10000.filter(Options.class::isInstance); Options.class.getClass(); return (Options)var10000.map(Options.class::cast).findFirst().orElse(this.options); } else { return this.options; } } static class Factory { private final Client client; private final Retryer retryer; private final List<RequestInterceptor> requestInterceptors; private final Logger logger; private final Level logLevel; private final boolean decode404; private final boolean closeAfterDecode; private final ExceptionPropagationPolicy propagationPolicy; private final boolean forceDecoding; Factory(Client client, Retryer retryer, List<RequestInterceptor> requestInterceptors, Logger logger, Level logLevel, boolean decode404, boolean closeAfterDecode, ExceptionPropagationPolicy propagationPolicy, boolean forceDecoding) { this.client = (Client)Util.checkNotNull(client, "client", new Object[0]); this.retryer = (Retryer)Util.checkNotNull(retryer, "retryer", new Object[0]); this.requestInterceptors = (List)Util.checkNotNull(requestInterceptors, "requestInterceptors", new Object[0]); this.logger = (Logger)Util.checkNotNull(logger, "logger", new Object[0]); this.logLevel = (Level)Util.checkNotNull(logLevel, "logLevel", new Object[0]); this.decode404 = decode404; this.closeAfterDecode = closeAfterDecode; this.propagationPolicy = propagationPolicy; this.forceDecoding = forceDecoding; } public MethodHandler create(Target<?> target, MethodMetadata md, feign.RequestTemplate.Factory buildTemplateFromArgs, Options options, Decoder decoder, ErrorDecoder errorDecoder) { return new SynchronousMethodHandler(target, this.client, this.retryer, this.requestInterceptors, this.logger, this.logLevel, md, buildTemplateFromArgs, options, decoder, errorDecoder, this.decode404, this.closeAfterDecode, this.propagationPolicy, this.forceDecoding); } } } 远程调用时,构建了RequestInterceptor。自定义feign拦截器import feign.RequestInterceptor; import feign.RequestTemplate; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.web.context.request.RequestContextHolder; import org.springframework.web.context.request.ServletRequestAttributes; import javax.servlet.http.HttpServletRequest; /** * @description: TODO * @author: <a href="mailto:batis@foxmail.com">清风</a> * @date: 2022/3/10 23:03 * @version: 1.0 */ @Configuration public class FamilyFegin { @Bean(name ="requestInterceptor") public RequestInterceptor requestInterceptor(){ return new RequestInterceptor() { @Override public void apply(RequestTemplate requestTemplate) { //RequestContextHolder拿到刚请求来的数据 ServletRequestAttributes requestAttributes = (ServletRequestAttributes)RequestContextHolder.getRequestAttributes(); HttpServletRequest request = requestAttributes.getRequest(); System.out.println("调用feign之前"); //同步请求头数据 String cookie = request.getHeader("Cookie");//老数据 //给新请求同步老请求的cookie requestTemplate.header("Cookie", cookie); } }; } }拦截器说明RequestContextHolder.getRequestAttributes()获取到RequestAttributes类,RequestAttributes源码:// // Source code recreated from a .class file by IntelliJ IDEA // (powered by FernFlower decompiler) // package org.springframework.web.context.request; import org.springframework.lang.Nullable; public interface RequestAttributes { int SCOPE_REQUEST = 0; int SCOPE_SESSION = 1; String REFERENCE_REQUEST = "request"; String REFERENCE_SESSION = "session"; @Nullable Object getAttribute(String var1, int var2); void setAttribute(String var1, Object var2, int var3); void removeAttribute(String var1, int var2); String[] getAttributeNames(int var1); void registerDestructionCallback(String var1, Runnable var2, int var3); @Nullable Object resolveReference(String var1); String getSessionId(); Object getSessionMutex(); } ServletRequestAttributes继承了AbstractRequestAttributes,AbstractRequestAttributes实现了RequestAttributes,因此可以强转。 public abstract class AbstractRequestAttributes implements RequestAttributes { protected final Map<String, Runnable> requestDestructionCallbacks = new LinkedHashMap(8); private volatile boolean requestActive = true; public AbstractRequestAttributes() { } public void requestCompleted() {注意:该处理是在同步一个线程种处理的,才能获取之前的heard中的cookie信息。异步多线程该处理方式不同。
-
-
![[ERR] 1067 - Invalid default value for 'created_date_' [ERR]](https://www.yanxizhu.com/usr/themes/Joe/assets/thumb/42.jpg)