搜索到
26
篇与
的结果
-
 JAVA8-自定义Spliterator JAVA8-自定义Spliterator需求说明:将一段话按换行符分割成多个执行,并输出。package com.example.study.java8.forkjoin; import java.util.Objects; import java.util.Spliterator; import java.util.function.Consumer; import java.util.stream.Stream; import java.util.stream.StreamSupport; /** * 自定义Spliterator * 实列:将一段话按换行符分割成多个执行,并输出。 */ public class SpliteratorInAction { //需要处理的数据 private static String text = "The tryAdvance method feeds the Consumer with the Character in the String at the current index\n" + "position and increments this position. The Consumer passed as argument is an internal Java class\n" + "forwarding the consumed Character to the set of functions that have to be applied to it while\n" + "traversing the stream, which in this case is only a reducing function, namely, the accumulate method\n" + "of the WordCounter class. The tryAdvance method returns true if the new cursor position is less\n" + "than the total String length and there are further Characters to be iterated.\n" + "\uF0B7 The trySplit method is the most important one in a Spliterator because it’s the one defining the\n" + "logic used to split the data structure to be iterated. As you did in the compute method of the\n" + "RecursiveTask implemented in listing 7.1 (on how to use the fork/join framework), the first thing\n" + "you have to do here is set a limit under which you don’t want to perform further splits. Here, you use a\n" + "very low limit of 10 Characters only to make sure that your program will perform some splits with\n" + "the relatively short String you’re parsing, but in real-world applications you’ll have to use a higher\n" + "limit, as you did in the fork/join example, to avoid creating too many tasks. If the number of\n" + "remaining Characters to be traversed is under this limit, you return null to signal that no further\n" + "split is necessary. Conversely, if you need to perform a split, you set the candidate split position to the\n" + "half of the String chunk remaining to be parsed. But you don’t use this split position directly because\n" + "www.it-ebooks.info\n" + "231\n" + "you want to avoid splitting in the middle of a word, so you move forward until you find a blank\n" + "Character. Once you find an opportune split position, you create a new Spliterator that will traverse\n" + "the substring chunk going from the current position to the split one; you set the current position of\n" + "this to the split one, because the part before it will be managed by the new Spliterator, and then you\n" + "return it.\n" + "\uF0B7 The estimatedSize of elements still to be traversed is the difference between the total length of the\n" + "String parsed by this Spliterator and the position currently iterated.\n" + "\uF0B7 Finally, the characteristic method signals to the framework that this Spliterator is ORDERED\n" + "(the order is just the sequence of Characters in the String), SIZED (the value returned by the\n" + "estimatedSize method is exact), SUBSIZED (the other Spliterators created by the trySplit\n" + "method also have an exact size), NONNULL (there can be no null Characters in the String), and\n" + "IMMUTABLE (no further Characters can be added while parsing the String because the String\n" + "itself is an immutable class)."; public static void main(String[] args) { //测试 // IntStream intStream = IntStream.rangeClosed(1, 10); // Spliterator.OfInt spliterator = intStream.spliterator(); // Consumer<Integer> integerConsumer = i-> System.out.println(i); // spliterator.forEachRemaining(integerConsumer); MySpliteratorText mySpliteratorText = new MySpliteratorText(text); //串行调用 // Optional.ofNullable(mySpliteratorText.stream().count()) // .ifPresent(System.out::println); // mySpliteratorText.stream().forEach(System.out::println); //并行执行 mySpliteratorText.stream().filter(s -> !"".equals(s)).forEach(System.out::println); mySpliteratorText.parallelStream().filter(s -> !"".equals(s)).forEach(System.out::println); } /** * 自定义Spliterator */ static class MySpliteratorText { private final String[] data; public MySpliteratorText(String text) { Objects.requireNonNull(text, "Ths parameter can not be null"); this.data = text.split("\n"); } //暴露使用方法,穿行 public Stream<String> stream() { return StreamSupport.stream(new MySpliterator(), false); } //暴露使用方法,并行 public Stream<String> parallelStream() { return StreamSupport.stream(new MySpliterator(), true); } private class MySpliterator implements Spliterator<String> { private int start, end; public MySpliterator() { this.start = 0; this.end = MySpliteratorText.this.data.length - 1; } public MySpliterator(int start, int end) { this.start = start; this.end = end; } /** * 不管串行还是并行都会执行,有数据就进行Consumer,没有就返回false; * * @param action * @return */ @Override public boolean tryAdvance(Consumer<? super String> action) { //元素是有的,就进行消费 if (start <= end) { action.accept(MySpliteratorText.this.data[start++]); return true; } return false; } @Override public Spliterator<String> trySplit() { int mid = (end - start) / 2; //没有可拆的 if (mid <= 1) { return null; } int left = start; int right = start + mid; start = start + mid + 1; return new MySpliterator(left, right); } @Override public long estimateSize() { return end - start; } @Override public long getExactSizeIfKnown() { return estimateSize(); } @Override public int characteristics() { return IMMUTABLE | SIZED | SUBSIZED; } } } } 串行调用输出结果:The tryAdvance method feeds the Consumer with the Character in the String at the current index position and increments this position. The Consumer passed as argument is an internal Java class forwarding the consumed Character to the set of functions that have to be applied to it while traversing the stream, which in this case is only a reducing function, namely, the accumulate method of the WordCounter class. The tryAdvance method returns true if the new cursor position is less than the total String length and there are further Characters to be iterated. The trySplit method is the most important one in a Spliterator because it’s the one defining the logic used to split the data structure to be iterated. As you did in the compute method of the RecursiveTask implemented in listing 7.1 (on how to use the fork/join framework), the first thing you have to do here is set a limit under which you don’t want to perform further splits. Here, you use a very low limit of 10 Characters only to make sure that your program will perform some splits with the relatively short String you’re parsing, but in real-world applications you’ll have to use a higher limit, as you did in the fork/join example, to avoid creating too many tasks. If the number of remaining Characters to be traversed is under this limit, you return null to signal that no further split is necessary. Conversely, if you need to perform a split, you set the candidate split position to the half of the String chunk remaining to be parsed. But you don’t use this split position directly because www.it-ebooks.info 231 you want to avoid splitting in the middle of a word, so you move forward until you find a blank Character. Once you find an opportune split position, you create a new Spliterator that will traverse the substring chunk going from the current position to the split one; you set the current position of this to the split one, because the part before it will be managed by the new Spliterator, and then you return it. The estimatedSize of elements still to be traversed is the difference between the total length of the String parsed by this Spliterator and the position currently iterated. Finally, the characteristic method signals to the framework that this Spliterator is ORDERED (the order is just the sequence of Characters in the String), SIZED (the value returned by the estimatedSize method is exact), SUBSIZED (the other Spliterators created by the trySplit method also have an exact size), NONNULL (there can be no null Characters in the String), and IMMUTABLE (no further Characters can be added while parsing the String because the String itself is an immutable class).并行调用输出结果:The tryAdvance method feeds the Consumer with the Character in the String at the current index position and increments this position. The Consumer passed as argument is an internal Java class forwarding the consumed Character to the set of functions that have to be applied to it while traversing the stream, which in this case is only a reducing function, namely, the accumulate method of the WordCounter class. The tryAdvance method returns true if the new cursor position is less than the total String length and there are further Characters to be iterated. The trySplit method is the most important one in a Spliterator because it’s the one defining the logic used to split the data structure to be iterated. As you did in the compute method of the RecursiveTask implemented in listing 7.1 (on how to use the fork/join framework), the first thing you have to do here is set a limit under which you don’t want to perform further splits. Here, you use a very low limit of 10 Characters only to make sure that your program will perform some splits with the relatively short String you’re parsing, but in real-world applications you’ll have to use a higher limit, as you did in the fork/join example, to avoid creating too many tasks. If the number of remaining Characters to be traversed is under this limit, you return null to signal that no further split is necessary. Conversely, if you need to perform a split, you set the candidate split position to the half of the String chunk remaining to be parsed. But you don’t use this split position directly because www.it-ebooks.info 231 you want to avoid splitting in the middle of a word, so you move forward until you find a blank Character. Once you find an opportune split position, you create a new Spliterator that will traverse the substring chunk going from the current position to the split one; you set the current position of this to the split one, because the part before it will be managed by the new Spliterator, and then you return it. The estimatedSize of elements still to be traversed is the difference between the total length of the String parsed by this Spliterator and the position currently iterated. Finally, the characteristic method signals to the framework that this Spliterator is ORDERED (the order is just the sequence of Characters in the String), SIZED (the value returned by the estimatedSize method is exact), SUBSIZED (the other Spliterators created by the trySplit method also have an exact size), NONNULL (there can be no null Characters in the String), and IMMUTABLE (no further Characters can be added while parsing the String because the String itself is an immutable class). the substring chunk going from the current position to the split one; you set the current position of this to the split one, because the part before it will be managed by the new Spliterator, and then you return it. The estimatedSize of elements still to be traversed is the difference between the total length of the www.it-ebooks.info 231 you want to avoid splitting in the middle of a word, so you move forward until you find a blank Character. Once you find an opportune split position, you create a new Spliterator that will traverse method also have an exact size), NONNULL (there can be no null Characters in the String), and IMMUTABLE (no further Characters can be added while parsing the String because the String itself is an immutable class). String parsed by this Spliterator and the position currently iterated. Finally, the characteristic method signals to the framework that this Spliterator is ORDERED (the order is just the sequence of Characters in the String), SIZED (the value returned by the estimatedSize method is exact), SUBSIZED (the other Spliterators created by the trySplit of the WordCounter class. The tryAdvance method returns true if the new cursor position is less than the total String length and there are further Characters to be iterated. The trySplit method is the most important one in a Spliterator because it’s the one defining the logic used to split the data structure to be iterated. As you did in the compute method of the The tryAdvance method feeds the Consumer with the Character in the String at the current index limit, as you did in the fork/join example, to avoid creating too many tasks. If the number of remaining Characters to be traversed is under this limit, you return null to signal that no further split is necessary. Conversely, if you need to perform a split, you set the candidate split position to the half of the String chunk remaining to be parsed. But you don’t use this split position directly because RecursiveTask implemented in listing 7.1 (on how to use the fork/join framework), the first thing you have to do here is set a limit under which you don’t want to perform further splits. Here, you use a very low limit of 10 Characters only to make sure that your program will perform some splits with the relatively short String you’re parsing, but in real-world applications you’ll have to use a higher position and increments this position. The Consumer passed as argument is an internal Java class forwarding the consumed Character to the set of functions that have to be applied to it while traversing the stream, which in this case is only a reducing function, namely, the accumulate method Disconnected from the target VM, address: '127.0.0.1:2490', transport: 'socket'说明://测试 IntStream intStream = IntStream.rangeClosed(1, 10); Spliterator.OfInt spliterator = intStream.spliterator(); Consumer<Integer> integerConsumer = i-> System.out.println(i); spliterator.forEachRemaining(integerConsumer);Spliterator.OfInt其实就是Spliterator的子类,源码:public interface OfInt extends OfPrimitive<Integer, IntConsumer, OfInt> { }
JAVA8-自定义Spliterator JAVA8-自定义Spliterator需求说明:将一段话按换行符分割成多个执行,并输出。package com.example.study.java8.forkjoin; import java.util.Objects; import java.util.Spliterator; import java.util.function.Consumer; import java.util.stream.Stream; import java.util.stream.StreamSupport; /** * 自定义Spliterator * 实列:将一段话按换行符分割成多个执行,并输出。 */ public class SpliteratorInAction { //需要处理的数据 private static String text = "The tryAdvance method feeds the Consumer with the Character in the String at the current index\n" + "position and increments this position. The Consumer passed as argument is an internal Java class\n" + "forwarding the consumed Character to the set of functions that have to be applied to it while\n" + "traversing the stream, which in this case is only a reducing function, namely, the accumulate method\n" + "of the WordCounter class. The tryAdvance method returns true if the new cursor position is less\n" + "than the total String length and there are further Characters to be iterated.\n" + "\uF0B7 The trySplit method is the most important one in a Spliterator because it’s the one defining the\n" + "logic used to split the data structure to be iterated. As you did in the compute method of the\n" + "RecursiveTask implemented in listing 7.1 (on how to use the fork/join framework), the first thing\n" + "you have to do here is set a limit under which you don’t want to perform further splits. Here, you use a\n" + "very low limit of 10 Characters only to make sure that your program will perform some splits with\n" + "the relatively short String you’re parsing, but in real-world applications you’ll have to use a higher\n" + "limit, as you did in the fork/join example, to avoid creating too many tasks. If the number of\n" + "remaining Characters to be traversed is under this limit, you return null to signal that no further\n" + "split is necessary. Conversely, if you need to perform a split, you set the candidate split position to the\n" + "half of the String chunk remaining to be parsed. But you don’t use this split position directly because\n" + "www.it-ebooks.info\n" + "231\n" + "you want to avoid splitting in the middle of a word, so you move forward until you find a blank\n" + "Character. Once you find an opportune split position, you create a new Spliterator that will traverse\n" + "the substring chunk going from the current position to the split one; you set the current position of\n" + "this to the split one, because the part before it will be managed by the new Spliterator, and then you\n" + "return it.\n" + "\uF0B7 The estimatedSize of elements still to be traversed is the difference between the total length of the\n" + "String parsed by this Spliterator and the position currently iterated.\n" + "\uF0B7 Finally, the characteristic method signals to the framework that this Spliterator is ORDERED\n" + "(the order is just the sequence of Characters in the String), SIZED (the value returned by the\n" + "estimatedSize method is exact), SUBSIZED (the other Spliterators created by the trySplit\n" + "method also have an exact size), NONNULL (there can be no null Characters in the String), and\n" + "IMMUTABLE (no further Characters can be added while parsing the String because the String\n" + "itself is an immutable class)."; public static void main(String[] args) { //测试 // IntStream intStream = IntStream.rangeClosed(1, 10); // Spliterator.OfInt spliterator = intStream.spliterator(); // Consumer<Integer> integerConsumer = i-> System.out.println(i); // spliterator.forEachRemaining(integerConsumer); MySpliteratorText mySpliteratorText = new MySpliteratorText(text); //串行调用 // Optional.ofNullable(mySpliteratorText.stream().count()) // .ifPresent(System.out::println); // mySpliteratorText.stream().forEach(System.out::println); //并行执行 mySpliteratorText.stream().filter(s -> !"".equals(s)).forEach(System.out::println); mySpliteratorText.parallelStream().filter(s -> !"".equals(s)).forEach(System.out::println); } /** * 自定义Spliterator */ static class MySpliteratorText { private final String[] data; public MySpliteratorText(String text) { Objects.requireNonNull(text, "Ths parameter can not be null"); this.data = text.split("\n"); } //暴露使用方法,穿行 public Stream<String> stream() { return StreamSupport.stream(new MySpliterator(), false); } //暴露使用方法,并行 public Stream<String> parallelStream() { return StreamSupport.stream(new MySpliterator(), true); } private class MySpliterator implements Spliterator<String> { private int start, end; public MySpliterator() { this.start = 0; this.end = MySpliteratorText.this.data.length - 1; } public MySpliterator(int start, int end) { this.start = start; this.end = end; } /** * 不管串行还是并行都会执行,有数据就进行Consumer,没有就返回false; * * @param action * @return */ @Override public boolean tryAdvance(Consumer<? super String> action) { //元素是有的,就进行消费 if (start <= end) { action.accept(MySpliteratorText.this.data[start++]); return true; } return false; } @Override public Spliterator<String> trySplit() { int mid = (end - start) / 2; //没有可拆的 if (mid <= 1) { return null; } int left = start; int right = start + mid; start = start + mid + 1; return new MySpliterator(left, right); } @Override public long estimateSize() { return end - start; } @Override public long getExactSizeIfKnown() { return estimateSize(); } @Override public int characteristics() { return IMMUTABLE | SIZED | SUBSIZED; } } } } 串行调用输出结果:The tryAdvance method feeds the Consumer with the Character in the String at the current index position and increments this position. The Consumer passed as argument is an internal Java class forwarding the consumed Character to the set of functions that have to be applied to it while traversing the stream, which in this case is only a reducing function, namely, the accumulate method of the WordCounter class. The tryAdvance method returns true if the new cursor position is less than the total String length and there are further Characters to be iterated. The trySplit method is the most important one in a Spliterator because it’s the one defining the logic used to split the data structure to be iterated. As you did in the compute method of the RecursiveTask implemented in listing 7.1 (on how to use the fork/join framework), the first thing you have to do here is set a limit under which you don’t want to perform further splits. Here, you use a very low limit of 10 Characters only to make sure that your program will perform some splits with the relatively short String you’re parsing, but in real-world applications you’ll have to use a higher limit, as you did in the fork/join example, to avoid creating too many tasks. If the number of remaining Characters to be traversed is under this limit, you return null to signal that no further split is necessary. Conversely, if you need to perform a split, you set the candidate split position to the half of the String chunk remaining to be parsed. But you don’t use this split position directly because www.it-ebooks.info 231 you want to avoid splitting in the middle of a word, so you move forward until you find a blank Character. Once you find an opportune split position, you create a new Spliterator that will traverse the substring chunk going from the current position to the split one; you set the current position of this to the split one, because the part before it will be managed by the new Spliterator, and then you return it. The estimatedSize of elements still to be traversed is the difference between the total length of the String parsed by this Spliterator and the position currently iterated. Finally, the characteristic method signals to the framework that this Spliterator is ORDERED (the order is just the sequence of Characters in the String), SIZED (the value returned by the estimatedSize method is exact), SUBSIZED (the other Spliterators created by the trySplit method also have an exact size), NONNULL (there can be no null Characters in the String), and IMMUTABLE (no further Characters can be added while parsing the String because the String itself is an immutable class).并行调用输出结果:The tryAdvance method feeds the Consumer with the Character in the String at the current index position and increments this position. The Consumer passed as argument is an internal Java class forwarding the consumed Character to the set of functions that have to be applied to it while traversing the stream, which in this case is only a reducing function, namely, the accumulate method of the WordCounter class. The tryAdvance method returns true if the new cursor position is less than the total String length and there are further Characters to be iterated. The trySplit method is the most important one in a Spliterator because it’s the one defining the logic used to split the data structure to be iterated. As you did in the compute method of the RecursiveTask implemented in listing 7.1 (on how to use the fork/join framework), the first thing you have to do here is set a limit under which you don’t want to perform further splits. Here, you use a very low limit of 10 Characters only to make sure that your program will perform some splits with the relatively short String you’re parsing, but in real-world applications you’ll have to use a higher limit, as you did in the fork/join example, to avoid creating too many tasks. If the number of remaining Characters to be traversed is under this limit, you return null to signal that no further split is necessary. Conversely, if you need to perform a split, you set the candidate split position to the half of the String chunk remaining to be parsed. But you don’t use this split position directly because www.it-ebooks.info 231 you want to avoid splitting in the middle of a word, so you move forward until you find a blank Character. Once you find an opportune split position, you create a new Spliterator that will traverse the substring chunk going from the current position to the split one; you set the current position of this to the split one, because the part before it will be managed by the new Spliterator, and then you return it. The estimatedSize of elements still to be traversed is the difference between the total length of the String parsed by this Spliterator and the position currently iterated. Finally, the characteristic method signals to the framework that this Spliterator is ORDERED (the order is just the sequence of Characters in the String), SIZED (the value returned by the estimatedSize method is exact), SUBSIZED (the other Spliterators created by the trySplit method also have an exact size), NONNULL (there can be no null Characters in the String), and IMMUTABLE (no further Characters can be added while parsing the String because the String itself is an immutable class). the substring chunk going from the current position to the split one; you set the current position of this to the split one, because the part before it will be managed by the new Spliterator, and then you return it. The estimatedSize of elements still to be traversed is the difference between the total length of the www.it-ebooks.info 231 you want to avoid splitting in the middle of a word, so you move forward until you find a blank Character. Once you find an opportune split position, you create a new Spliterator that will traverse method also have an exact size), NONNULL (there can be no null Characters in the String), and IMMUTABLE (no further Characters can be added while parsing the String because the String itself is an immutable class). String parsed by this Spliterator and the position currently iterated. Finally, the characteristic method signals to the framework that this Spliterator is ORDERED (the order is just the sequence of Characters in the String), SIZED (the value returned by the estimatedSize method is exact), SUBSIZED (the other Spliterators created by the trySplit of the WordCounter class. The tryAdvance method returns true if the new cursor position is less than the total String length and there are further Characters to be iterated. The trySplit method is the most important one in a Spliterator because it’s the one defining the logic used to split the data structure to be iterated. As you did in the compute method of the The tryAdvance method feeds the Consumer with the Character in the String at the current index limit, as you did in the fork/join example, to avoid creating too many tasks. If the number of remaining Characters to be traversed is under this limit, you return null to signal that no further split is necessary. Conversely, if you need to perform a split, you set the candidate split position to the half of the String chunk remaining to be parsed. But you don’t use this split position directly because RecursiveTask implemented in listing 7.1 (on how to use the fork/join framework), the first thing you have to do here is set a limit under which you don’t want to perform further splits. Here, you use a very low limit of 10 Characters only to make sure that your program will perform some splits with the relatively short String you’re parsing, but in real-world applications you’ll have to use a higher position and increments this position. The Consumer passed as argument is an internal Java class forwarding the consumed Character to the set of functions that have to be applied to it while traversing the stream, which in this case is only a reducing function, namely, the accumulate method Disconnected from the target VM, address: '127.0.0.1:2490', transport: 'socket'说明://测试 IntStream intStream = IntStream.rangeClosed(1, 10); Spliterator.OfInt spliterator = intStream.spliterator(); Consumer<Integer> integerConsumer = i-> System.out.println(i); spliterator.forEachRemaining(integerConsumer);Spliterator.OfInt其实就是Spliterator的子类,源码:public interface OfInt extends OfPrimitive<Integer, IntConsumer, OfInt> { } -
JAVA8-Fork Join JAVA8-Fork JoinFork:将一个任务拆分成多个线程执行。Join:将每个现场结果join,最后得到结果。范例:求数组总和前置数据:public static int[] data = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};1、原始实现方式 public static int calc() { int result = 0; for (int i = 0; i < data.length; i++) { result += data[i]; } return result; }原始实现方式调用:System.out.println("result=> " + calc());2、RecursiveTask实现RecursiveTask有返回值。package com.example.study.java8.forkjoin; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import lombok.ToString; import java.util.concurrent.RecursiveTask; @Data @AllArgsConstructor @NoArgsConstructor @ToString public class AccumulatorRecursiveTask extends RecursiveTask<Integer> { private int start; private int end; private int[] data; private int LIMIT=3; public AccumulatorRecursiveTask(int start, int end, int[] data) { this.start = start; this.end = end; this.data = data; } @Override protected Integer compute() { //如果小于3个就可以直接进行计算了,否则fork成多个,再计算 if(end -start <LIMIT) { int result =0; for(int i=start;i<end;i++){ result+=data[i]; } return result; } int mid = (start+end)/2; AccumulatorRecursiveTask left = new AccumulatorRecursiveTask(start,mid,data); AccumulatorRecursiveTask right = new AccumulatorRecursiveTask(mid,end,data); left.fork(); Integer rightResult = right.compute(); Integer leftResult = left.join(); return rightResult+leftResult; } } RecursiveTask调用: AccumulatorRecursiveTask task = new AccumulatorRecursiveTask(0, data.length, data); ForkJoinPool forkJoinPool = new ForkJoinPool(); Integer result = forkJoinPool.invoke(task); System.out.println("AccumulatorRecursiveTask result => " + result);3、RecursiveAction实现RecursiveAction:无返回值package com.example.study.java8.forkjoin; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import lombok.ToString; import java.util.concurrent.RecursiveAction; import java.util.concurrent.atomic.AtomicInteger; @Data @AllArgsConstructor @NoArgsConstructor @ToString public class AccumulatorRecursiveAction extends RecursiveAction { private int start; private int end; private int[] data; private int LIMIT = 3; public AccumulatorRecursiveAction(int start, int end, int[] data) { this.start = start; this.end = end; this.data = data; } @Override protected void compute() { //如果小于3个就可以直接进行计算了,否则fork成多个,再计算 if (end - start < LIMIT) { for (int i = start; i < end; i++) { AccumulatorHelper.accumulate(data[i]); } } else { int mid = (start + end) / 2; AccumulatorRecursiveAction left = new AccumulatorRecursiveAction(start, mid, data); AccumulatorRecursiveAction right = new AccumulatorRecursiveAction(mid, end, data); right.fork(); left.fork(); right.join(); left.join(); } } static class AccumulatorHelper { private static final AtomicInteger result = new AtomicInteger(0); static void accumulate(int value) { result.getAndAdd(value); } public static int getResult() { return result.get(); } static void rest() { result.set(0); } } } RecursiveAction调用: AccumulatorRecursiveAction action = new AccumulatorRecursiveAction(0, data.length, data); forkJoinPool.invoke(action); System.out.println("AccumulatorRecursiveAction result => " + AccumulatorRecursiveAction.AccumulatorHelper.getResult());最后输出结果result=> 55 AccumulatorRecursiveTask result => 55 AccumulatorRecursiveAction result => 55
-
JAVA8-Stream parallel 并行执行 Stream parallel 并行执行范例:求1~100000000的和,执行10次,看时间效率。代码package com.example.study.java8.collector; import java.util.function.Function; import java.util.stream.LongStream; import java.util.stream.Stream; /** * Stream parallel并行执行 * 实列:求10次,1~100000000的和,看时间效率。 */ public class ParallelProcessing { public static void main(String[] args) { //获取电脑CPU核数 System.out.println("当前电脑CPU核数= " + Runtime.getRuntime().availableProcessors()); System.out.println("The best process time(normalAdd)=> " + measureSumPerformance(ParallelProcessing::normalAdd, 100_000_000) + " MS"); System.out.println("The best process time(iterateStream1)=> " + measureSumPerformance(ParallelProcessing::iterateStream1, 100_000_000) + " MS"); System.out.println("The best process time(iterateStream2)=> " + measureSumPerformance(ParallelProcessing::iterateStream2, 100_000_000) + " MS"); System.out.println("The best process time(iterateStream3)=> " + measureSumPerformance(ParallelProcessing::iterateStream3, 100_000_000) + " MS"); System.out.println("The best process time(iterateStream4)=> " + measureSumPerformance(ParallelProcessing::iterateStream4, 100_000_000) + " MS"); System.out.println("The best process time(iterateStream5)=> " + measureSumPerformance(ParallelProcessing::iterateStream5, 100_000_000) + " MS"); } private static long measureSumPerformance(Function<Long, Long> adder, long limist) { long fastest = Long.MAX_VALUE; for (int i = 0; i < 10; i++) { Long startTimestamp = System.currentTimeMillis(); long result = adder.apply(limist); long duration = System.currentTimeMillis() - startTimestamp; // System.out.println("The result of sum=>"+result); if (duration < fastest) fastest = duration; } return fastest; } /** * 1、函数式编程实现:没有使用并行执行 * * @param limit * @return */ public static long iterateStream1(long limit) { return Stream.iterate(1L, i -> i + 1).limit(limit).reduce(0L, Long::sum); } /** * 2、函数式编程实现-进化:使用并行执行,要进行拆箱装箱 * * @param limit * @return */ public static long iterateStream2(long limit) { return Stream.iterate(1L, i -> i + 1).parallel().limit(limit).reduce(0L, Long::sum); } /** * 3、函数式编程实现-再次进化:只用并行执行,不进行拆箱装箱 * * @param limit * @return */ public static long iterateStream3(long limit) { return Stream.iterate(1L, i -> i + 1).mapToLong(Long::longValue).parallel().limit(limit).reduce(0L, Long::sum); } /** * 4、函数式编程实现-再次再次进化:只用并行执行 * * @param limit * @return */ public static long iterateStream4(long limit) { return LongStream.rangeClosed(1L, limit).parallel().sum(); } /** * 5、函数式编程实现-再次再次再次进化 * * @param limit * @return */ public static long iterateStream5(long limit) { return LongStream.rangeClosed(1L, limit).parallel().reduce(0L, Long::sum); } /** * 原始写法 * * @param limit * @return */ public static long normalAdd(long limit) { long result = 0L; for (long i = 1; i < limit; i++) { result++; } return result; } } 输出结果当前电脑CPU核数= 16 The best process time(normalAdd)=> 29 MS The best process time(iterateStream1)=> 794 MS The best process time(iterateStream2)=> 2718 MS The best process time(iterateStream3)=> 2132 MS The best process time(iterateStream4)=> 6 MS The best process time(iterateStream5)=> 24 MS4和5效率差不多输出结果:当前电脑CPU核数= 16 The best process time(normalAdd)=> 29 MS The best process time(iterateStream4)=> 4 MS The best process time(iterateStream5)=> 5 MS结果可以看到使用LongStream的parallel并发执行效率最高。使用注意点Source DecomposabilityArrayList Excellent( 极好的)LinkedList Poor(不好的)IntStream.range Excellent( 极好的)Stream.iterate Poor(不好的)HashSet Good(好的)TreeSet Good(好的)上面的例子就是使用的LongStream.rangeClosed(),就是IntStream.range效率Excellent( 极好的)。
-
JAVA8-自定义Collector 自定义Collector实现Collector接口package com.example.study.java8.collector; import java.util.*; import java.util.function.BiConsumer; import java.util.function.BinaryOperator; import java.util.function.Function; import java.util.function.Supplier; import java.util.stream.Collector; /** * 自定义Collector * T:元素类型 * List<T>:要创建的类型 * List<T>:最后要返回的类型 */ public class ToListCollector<T> implements Collector<T, List<T>, List<T>> { private void log(final String log) { System.out.println(Thread.currentThread().getName()+"-"+log); } //一定时可变的supplier,不是固定值 @Override public Supplier<List<T>> supplier() { log("supplier"); return ArrayList::new; } //要进行的操作 @Override public BiConsumer<List<T>, T> accumulator() { log("accumulator"); return List::add; } //将结果整合 @Override public BinaryOperator<List<T>> combiner() { log("combiner"); return (list1,list2)->{ list1.addAll(list2); return list1; }; } //返回结果 @Override public Function<List<T>, List<T>> finisher() { log("finisher"); // return t->t; return Function.identity(); } //特征值:CONCURRENT-并行,UNORDERED-排序,IDENTITY_FINISH-入参就出参 @Override public Set<Characteristics> characteristics() { log("characteristics"); return Collections.unmodifiableSet(EnumSet.of(Characteristics.IDENTITY_FINISH, Characteristics.CONCURRENT)); } } 使用测试package com.example.study.java8.collector; import java.util.Arrays; import java.util.List; import java.util.stream.Collector; /** * 使用自定义Collector测试 */ public class CustomToListCollector { public static void main(String[] args) { String[] arrs = new String[]{"chinese","japanse","english","freach","Korean"}; //测试 //对应接口中的: //Supplier<A> supplier(), BiConsumer<A, T> accumulator(),Function<A, R> finisher(); Collector<String, List<String>, List<String>> collector = new ToListCollector<String>(); List<String> list = Arrays.stream(arrs).filter(s -> s.length() > 6).collect(collector); System.out.println(list); System.out.println("================================"); //parallelStream(),并行使用测试 List<String> parallelList = Arrays.asList(new String[]{"chinese", "japanse", "english", "freach", "Korean"}) .parallelStream() .filter(s -> s.length() > 6) .collect(collector); System.out.println(parallelList); } } 输出结果main-supplier main-accumulator main-combiner main-characteristics main-characteristics [chinese, japanse, english] ================================ main-characteristics main-characteristics main-supplier main-accumulator main-combiner main-characteristics main-characteristics [chinese, japanse, english]由于数据量少,并没有出现并行。
-
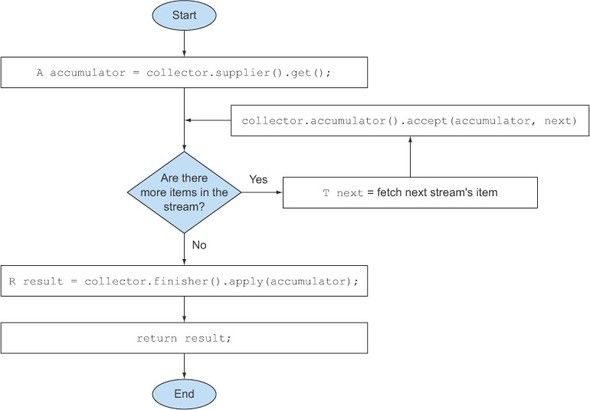
JAVA8-Collector interface源码分析 Collector interface源码分析源码public interface Collector<T, A, R> { Supplier<A> supplier(); BiConsumer<A, T> accumulator(); Function<A, R> finisher(); BinaryOperator<A> combiner(); Set<Characteristics> characteristics(); }说明:1.T is the generic type of the items in the stream to be collected.2.A is the type of the accumulator, the object on which the partial result will be accumulated during thecollection process.3.R is the type of the object (typically, but not always, the collection) resulting from the collectoperation.T:传入参数类型,A:需要进行处理的方法,R:处理后返回的结果特征值:CONCURRENT:并行的UNORDERED:无序的IDENTITY_FINISH:传入什么,返回什么范例toList()源码1、入口menu.stream().filter(t->t.isVegetarian()).collect(Collectors.toList())2、Collectors.toList()源码: public static <T> Collector<T, ?, List<T>> toList() { return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add, (left, right) -> { left.addAll(right); return left; }, CH_ID); }3、最后也就是Collector接口 CollectorImpl(Supplier<A> supplier, BiConsumer<A, T> accumulator, BinaryOperator<A> combiner, Set<Characteristics> characteristics) { this(supplier, accumulator, combiner, castingIdentity(), characteristics); }流程图1、Collector执行流程图 执行过程:通过Supplier supplier创建一个Container容器。查看stream里面是否还有元素。如果有,通过带2个入参一个返回结果参数的BiConsumer<A, T> accumulator进行数据处理。处理完后通过finisher返回执行结果。collect源码: 说明:1、获取容器container = collector.supplier().get(); 2、通过accumulator进行处理forEach(u -> accumulator.accept(container, u));3、执行完,返回执行结果return collector.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)2、combiner并行执行执行流程图 产生多个supplier并行处理,然后将多个处理结果combiner成一个,然后将结果返回。
-
JAVA8-Collectors API:summingDouble、summingInt、testSummingLong、toCollection、toConcurrentMap、toList、toSet、toMap JAVA8-Collectors API:summingDouble、summingInt、testSummingLong、toCollection、toConcurrentMap、toList、toSet、toMap前置数据 public static final List<Dish> menu = Arrays.asList( new Dish("pork", false, 800, Dish.Type.MEAT), new Dish("beef", false, 700, Dish.Type.MEAT), new Dish("chicken", false, 400, Dish.Type.MEAT), new Dish("french fries", true, 530, Dish.Type.OTHER), new Dish("rice", true, 350, Dish.Type.OTHER), new Dish("season fruit", true, 120, Dish.Type.OTHER), new Dish("pizza", true, 550, Dish.Type.OTHER), new Dish("prawns", false, 300, Dish.Type.FISH), new Dish("salmon", false, 450, Dish.Type.FISH));范例:1、summingDouble public static void testAveragingDouble(){ System.out.println("testAveragingDouble"); //用reduce聚合求和 Optional.ofNullable(menu.stream().map(Dish::getCalories).reduce(Integer::sum)).get().ifPresent(System.out::println); //用collectors averagingDouble求平均值 Optional.ofNullable(menu.stream().collect(averagingDouble(Dish::getCalories))).ifPresent(System.out::println); }输出结果:testSummingDouble 4200.0 42002、summingDouble public static void testSummingInt() { System.out.println("testSummingInt"); Optional.ofNullable(menu.stream().collect(Collectors.summingInt(Dish::getCalories))).ifPresent(System.out::println); }输出结果:testSummingInt 42003、summingLong public static void testSummingLong() { System.out.println("testSummingLong"); Optional.ofNullable(menu.stream().collect(Collectors.summingLong(Dish::getCalories))).ifPresent(System.out::println); }输出结果:testSummingLong 42004、toCollection 返回Collection子类 public static void testToCollection() { System.out.println("testToCollection"); Optional.ofNullable(menu.stream().collect(Collectors.toCollection(LinkedList::new))).ifPresent(System.out::println); }输出结果:testToCollection [Dish{name='pork', vegetarian=false, calories=800, type=MEAT}, Dish{name='beef', vegetarian=false, calories=700, type=MEAT}, Dish{name='chicken', vegetarian=false, calories=400, type=MEAT}, Dish{name='french fries', vegetarian=true, calories=530, type=OTHER}, Dish{name='rice', vegetarian=true, calories=350, type=OTHER}, Dish{name='season fruit', vegetarian=true, calories=120, type=OTHER}, Dish{name='pizza', vegetarian=true, calories=550, type=OTHER}, Dish{name='prawns', vegetarian=false, calories=300, type=FISH}, Dish{name='salmon', vegetarian=false, calories=450, type=FISH}]5、toConcurrentMap public static void testToConcurrentMap() { System.out.println("testToConcurrentMap"); Optional.ofNullable(menu.stream().collect(Collectors.toConcurrentMap(Dish::getName,Dish::getCalories))).ifPresent(System.out::println); }输出结果:testToConcurrentMap {season fruit=120, chicken=400, pizza=550, salmon=450, beef=700, pork=800, rice=350, french fries=530, prawns=300}6、toConcurrentMap 按类型统计个数 public static void testToConcurrentMapWithBinaryOperator() { System.out.println("testToConcurrentMapWithBinaryOperator"); Optional.ofNullable(menu.stream().collect(Collectors.toConcurrentMap(Dish::getType,v->1L,(a,b)->a+b))).ifPresent(v->{ System.out.println(v); System.out.println(v.getClass()); }); }输出结果:testToConcurrentMapWithBinaryOperator {OTHER=4, MEAT=3, FISH=2} class java.util.concurrent.ConcurrentHashMap7、toConcurrentMap 按类型统计个数,返回指定类型Map public static void testToConcurrentMapWithBinaryOperatorAndSupplier() { System.out.println("testToConcurrentMapWithBinaryOperatorAndSupplier"); Optional.ofNullable(menu.stream().collect(Collectors.toConcurrentMap(Dish::getType,v->1L,(a,b)->a+b, ConcurrentSkipListMap::new))).ifPresent(v->{ System.out.println(v); System.out.println(v.getClass()); }); }输出结果:testToConcurrentMapWithBinaryOperatorAndSupplier {MEAT=3, FISH=2, OTHER=4} class java.util.concurrent.ConcurrentSkipListMap8、toList 转成list public static void testTolist() { System.out.println("testTolist"); Optional.ofNullable(menu.stream().filter(t->t.isVegetarian()).collect(Collectors.toList())).ifPresent(v->{ System.out.println(v); System.out.println(v.getClass()); }); }输出结果:testTolist [Dish{name='french fries', vegetarian=true, calories=530, type=OTHER}, Dish{name='rice', vegetarian=true, calories=350, type=OTHER}, Dish{name='season fruit', vegetarian=true, calories=120, type=OTHER}, Dish{name='pizza', vegetarian=true, calories=550, type=OTHER}] class java.util.ArrayList9、toSett 转成Set public static void testToSet() { System.out.println("testToSet"); Optional.ofNullable(menu.stream().filter(t->t.isVegetarian()).collect(Collectors.toSet())).ifPresent(v->{ System.out.println(v); System.out.println(v.getClass()); }); }输出结果:testToSet [Dish{name='french fries', vegetarian=true, calories=530, type=OTHER}, Dish{name='season fruit', vegetarian=true, calories=120, type=OTHER}, Dish{name='pizza', vegetarian=true, calories=550, type=OTHER}, Dish{name='rice', vegetarian=true, calories=350, type=OTHER}] class java.util.HashSet10、toMappublic static void testToMap() { System.out.println("testToMap"); Optional.ofNullable(menu.stream().collect(Collectors.toMap(Dish::getName,Dish::getCalories))).ifPresent(v->{ System.out.println(v); System.out.println(v.getClass()); }); //转成线程安全的map Optional.ofNullable(menu.stream().collect(Collectors.collectingAndThen(Collectors.toMap(Dish::getName, Dish::getCalories), Collections::synchronizedMap))).ifPresent(v->{ System.out.println(v); System.out.println(v.getClass()); }); }输出结果:testToMap {season fruit=120, chicken=400, pizza=550, salmon=450, beef=700, pork=800, rice=350, french fries=530, prawns=300} class java.util.HashMap {season fruit=120, chicken=400, pizza=550, salmon=450, beef=700, pork=800, rice=350, french fries=530, prawns=300} class java.util.Collections$SynchronizedMap11、toMap 按类型统计个数public static void testToMapWithBinaryOperator() { System.out.println("testToMapWithBinaryOperator"); Optional.ofNullable(menu.stream().collect(Collectors.toMap(Dish::getType,v->1L,(a,b)->a+b))).ifPresent(v->{ System.out.println(v); System.out.println(v.getClass()); }); }输出结果:testToMapWithBinaryOperator {MEAT=3, FISH=2, OTHER=4} class java.util.HashMap12、toMap 按类型统计个数,返回指定类型Ma ##p public static void testToMapWithBinaryOperatorAndSupplier() { System.out.println("testToMapWithBinaryOperatorAndSupplier"); Optional.ofNullable(menu.stream().collect(Collectors.toMap(Dish::getType,v->1L,(a,b)->a+b, ConcurrentSkipListMap::new))).ifPresent(v->{ System.out.println(v); System.out.println(v.getClass()); }); }输出结果:testToMapWithBinaryOperatorAndSupplier {MEAT=3, FISH=2, OTHER=4} class java.util.concurrent.ConcurrentSkipListMap
-
JAVA8-Collectors API: partitioningBy、reducing、summarizingLong、summarizingInt、summarizingDouble JAVA8-Collectors API: partitioningBy、reducing、summarizingLong、summarizingInt、summarizingDouble前置数据: public static final List<Dish> menu = Arrays.asList( new Dish("pork", false, 800, Dish.Type.MEAT), new Dish("beef", false, 700, Dish.Type.MEAT), new Dish("chicken", false, 400, Dish.Type.MEAT), new Dish("french fries", true, 530, Dish.Type.OTHER), new Dish("rice", true, 350, Dish.Type.OTHER), new Dish("season fruit", true, 120, Dish.Type.OTHER), new Dish("pizza", true, 550, Dish.Type.OTHER), new Dish("prawns", false, 300, Dish.Type.FISH), new Dish("salmon", false, 450, Dish.Type.FISH));范例:1、partitioningBy 分组 public static void testPartitioningByWithPredicate() { System.out.println("testPartitioningByWithPredicate"); Map<Boolean, List<Dish>> collect = menu.stream().collect(Collectors.partitioningBy(Dish::isVegetarian)); Optional.ofNullable(collect).ifPresent(System.out::println); }输出结果:testPartitioningByWithPredicate {false=[Dish{name='pork', vegetarian=false, calories=800, type=MEAT}, Dish{name='beef', vegetarian=false, calories=700, type=MEAT}, Dish{name='chicken', vegetarian=false, calories=400, type=MEAT}, Dish{name='prawns', vegetarian=false, calories=300, type=FISH}, Dish{name='salmon', vegetarian=false, calories=450, type=FISH}], true=[Dish{name='french fries', vegetarian=true, calories=530, type=OTHER}, Dish{name='rice', vegetarian=true, calories=350, type=OTHER}, Dish{name='season fruit', vegetarian=true, calories=120, type=OTHER}, Dish{name='pizza', vegetarian=true, calories=550, type=OTHER}]}2、partitioningBy 分组后,再处理求平均数 public static void testPartitioningByWithPredicateAndCollecotr() { System.out.println("testPartitioningByWithPredicateAndCollecotr"); Map<Boolean, Double> collect = menu.stream().collect(Collectors.partitioningBy(Dish::isVegetarian, Collectors.averagingInt(Dish::getCalories))); Optional.ofNullable(collect).ifPresent(System.out::println); }输出结果:testPartitioningByWithPredicateAndCollecotr {false=530.0, true=387.5}3、reducing public static void testReducingBinaryOperator() { System.out.println("testReducingBinaryOperator"); Optional<Dish> collect = menu.stream().collect(Collectors.reducing(BinaryOperator.maxBy(Comparator.comparingInt(Dish::getCalories)))); collect.ifPresent(System.out::println); }输出结果:testReducingBinaryOperator Dish{name='pork', vegetarian=false, calories=800, type=MEAT}4、reducing public static void testReducingBinaryOperatorAndIdentity() { System.out.println("testReducingBinaryOperatorAndIdentity"); Integer collect = menu.stream().map(Dish::getCalories).collect(Collectors.reducing(0, (d1, d2) -> d1 + d2)); System.out.println(collect); }输出结果:testReducingBinaryOperatorAndIdentity 42005、reducing public static void testReducingBinaryOperatorAndIdentityAndFunction() { System.out.println("testReducingBinaryOperatorAndIdentityAndFunction"); Integer collect = menu.stream().collect(Collectors.reducing(0, Dish::getCalories,(d1, d2) -> d1 + d2)); System.out.println(collect); }输出结果:testReducingBinaryOperatorAndIdentityAndFunction 42006、summarizingDouble public static void testSummarizingDouble() { System.out.println("testSummarizingDouble"); DoubleSummaryStatistics collect = menu.stream().collect(Collectors.summarizingDouble(Dish::getCalories)); Optional.ofNullable(collect).ifPresent(System.out::println); }输出结果:testSummarizingDouble DoubleSummaryStatistics{count=9, sum=4200.000000, min=120.000000, average=466.666667, max=800.000000}7、summarizingInt public static void testSummarizingInt() { System.out.println("testSummarizingDouble"); IntSummaryStatistics collect = menu.stream().collect(Collectors.summarizingInt(Dish::getCalories)); Optional.ofNullable(collect).ifPresent(System.out::println); }输出结果:testSummarizingDouble IntSummaryStatistics{count=9, sum=4200, min=120, average=466.666667, max=800}8、summarizingLong public static void testSummarizingLong() { System.out.println("testSummarizingLong"); LongSummaryStatistics collect = menu.stream().collect(Collectors.summarizingLong(Dish::getCalories)); Optional.ofNullable(collect).ifPresent(System.out::println); }输出结果:testSummarizingLong LongSummaryStatistics{count=9, sum=4200, min=120, average=466.666667, max=800}
-
JAVA8-Collectors API: groupingByConcurrent、joining、mapping、maxby、minby JAVA8-Collectors API: groupingByConcurrent、joining、mapping、maxby、minby前置数据 public static final List<Dish> menu = Arrays.asList( new Dish("pork", false, 800, Dish.Type.MEAT), new Dish("beef", false, 700, Dish.Type.MEAT), new Dish("chicken", false, 400, Dish.Type.MEAT), new Dish("french fries", true, 530, Dish.Type.OTHER), new Dish("rice", true, 350, Dish.Type.OTHER), new Dish("season fruit", true, 120, Dish.Type.OTHER), new Dish("pizza", true, 550, Dish.Type.OTHER), new Dish("prawns", false, 300, Dish.Type.FISH), new Dish("salmon", false, 450, Dish.Type.FISH));范例:1、groupingByConcurrent 返回map为ConcurrentMap,按类型分组 public static void testGroupingByConcurrentWithFunction() { System.out.println("testGroupingByConcurrentWithFunction"); ConcurrentMap<Dish.Type, List<Dish>> collect = menu.stream().collect(Collectors.groupingByConcurrent(Dish::getType)); Optional.ofNullable(collect.getClass()).ifPresent(System.out::println); Optional.ofNullable(collect).ifPresent(System.out::println); }输出结果:testGroupingByConcurrentWithFunction class java.util.concurrent.ConcurrentHashMap {MEAT=[Dish{name='pork', vegetarian=false, calories=800, type=MEAT}, Dish{name='beef', vegetarian=false, calories=700, type=MEAT}, Dish{name='chicken', vegetarian=false, calories=400, type=MEAT}], FISH=[Dish{name='prawns', vegetarian=false, calories=300, type=FISH}, Dish{name='salmon', vegetarian=false, calories=450, type=FISH}], OTHER=[Dish{name='french fries', vegetarian=true, calories=530, type=OTHER}, Dish{name='rice', vegetarian=true, calories=350, type=OTHER}, Dish{name='season fruit', vegetarian=true, calories=120, type=OTHER}, Dish{name='pizza', vegetarian=true, calories=550, type=OTHER}]}2、groupingByConcurrent 返回map为ConcurrentMap,按按类型分组,并求平均值 public static void testGroupingByConcurrentWithFunctionAndCollector() { System.out.println("testGroupingByConcurrentWithFunctionAndCollector"); Map<Dish.Type, Double> collect = menu.stream().collect(Collectors.groupingByConcurrent(Dish::getType, Collectors.averagingInt(Dish::getCalories))); Optional.ofNullable(collect.getClass()).ifPresent(System.out::println); Optional.ofNullable(collect).ifPresent(System.out::println); }输出结果:testGroupingByConcurrentWithFunctionAndCollector class java.util.concurrent.ConcurrentHashMap {MEAT=633.3333333333334, FISH=375.0, OTHER=387.5}3、groupingByConcurrent 返回map为ConcurrentMap,按按类型分组,并求平均值,并修改返回类型为ConcurrentSkipListMap(跳表,以空间换时间的数据结构) public static void testGroupingByConcurrentWithFunctionAndSupplierAndCollector() { System.out.println("testGroupingByConcurrentWithFunctionAndSupplierAndCollector"); ConcurrentSkipListMap<Dish.Type, Double> collect = menu.stream().collect(Collectors.groupingByConcurrent(Dish::getType, ConcurrentSkipListMap::new, Collectors.averagingInt(Dish::getCalories))); Optional.ofNullable(collect.getClass()).ifPresent(System.out::println); Optional.ofNullable(collect).ifPresent(System.out::println); }输出结果:testGroupingByConcurrentWithFunctionAndSupplierAndCollector class java.util.concurrent.ConcurrentSkipListMap {MEAT=633.3333333333334, FISH=375.0, OTHER=387.5}4、joining 拼接,不能直接join public static void testJoin() { System.out.println("testJoin"); String collect = menu.stream().map(Dish::getName).collect(Collectors.joining()); Optional.ofNullable(collect).ifPresent(System.out::println); }输出结果:testJoin porkbeefchickenfrench friesriceseason fruitpizzaprawnssalmon5、joining 拼接,通过逗号拼接 public static void testJoinWithDelimiter() { System.out.println("testJoinWithDelimter"); String collect = menu.stream().map(Dish::getName).collect(Collectors.joining(",")); Optional.ofNullable(collect).ifPresent(System.out::println); }输出结果:testJoinWithDelimter pork,beef,chicken,french fries,rice,season fruit,pizza,prawns,salmon6、joining 拼接,通过逗号拼接,拼接后加前缀和后缀 public static void testJoinWithDelimiterAndPrefixAndSuffix() { System.out.println("testJoinWithDelimiterAndPrefixAndSuffix"); String collect = menu.stream().map(Dish::getName).collect(Collectors.joining(",","Names:[","]")); Optional.ofNullable(collect).ifPresent(System.out::println); }输出结果:testJoinWithDelimiterAndPrefixAndSuffix Names:[pork,beef,chicken,french fries,rice,season fruit,pizza,prawns,salmon]7、mapping 拼接,能直接join public static void testMapping() { System.out.println("testMapping"); String collect = menu.stream().collect(Collectors.mapping(Dish::getName, Collectors.joining(","))); Optional.ofNullable(collect).ifPresent(System.out::println); }输出结果:testMapping pork,beef,chicken,french fries,rice,season fruit,pizza,prawns,salmon8、maxBy 查找最大的一个Dish public static void testMaxBy() { System.out.println("testMaxBy"); Optional<Dish> collect = menu.stream().collect(Collectors.maxBy(Comparator.comparing(Dish::getCalories))); collect.ifPresent(System.out::println); }输出结果:testMaxBy Dish{name='pork', vegetarian=false, calories=800, type=MEAT}9、minBy 查找最小的一个Dish public static void testMinBy() { System.out.println("testMinBy"); Optional<Dish> collect = menu.stream().collect(Collectors.minBy(Comparator.comparing(Dish::getCalories))); collect.ifPresent(System.out::println); }输出结果:testMinBy Dish{name='season fruit', vegetarian=true, calories=120, type=OTHER}
-
JAVA8-Collectors API:averaging、collectingAndThen、counting、groupingBy JAVA8-Collectors API:averaging、collectingAndThen、counting、groupingBy前置数据 public static final List<Dish> menu = Arrays.asList( new Dish("pork", false, 800, Dish.Type.MEAT), new Dish("beef", false, 700, Dish.Type.MEAT), new Dish("chicken", false, 400, Dish.Type.MEAT), new Dish("french fries", true, 530, Dish.Type.OTHER), new Dish("rice", true, 350, Dish.Type.OTHER), new Dish("season fruit", true, 120, Dish.Type.OTHER), new Dish("pizza", true, 550, Dish.Type.OTHER), new Dish("prawns", false, 300, Dish.Type.FISH), new Dish("salmon", false, 450, Dish.Type.FISH));范例:1、averagingDouble 求平均值 public static void testAveragingDouble(){ System.out.println("testAveragingDouble"); //用reduce聚合求和 Optional.ofNullable(menu.stream().map(Dish::getCalories).reduce(Integer::sum)).get().ifPresent(System.out::println); //用collectors averagingDouble求平均值 Optional.ofNullable(menu.stream().collect(averagingDouble(Dish::getCalories))).ifPresent(System.out::println); }输出结果:testAveragingDouble 4200 466.66666666666672、averagingInt 求平均值 public static void testAveragingInt(){ System.out.println("testAveragingInt"); //用collectors averagingDouble求平均值 Optional.ofNullable(menu.stream().collect(averagingInt(Dish::getCalories))).ifPresent(System.out::println); }输出结果:testAveragingInt 466.66666666666673、averagingLong 求平均值 public static void testAveragingLong(){ System.out.println("testAveragingLong"); //用collectors averagingLong求平均值 Optional.ofNullable(menu.stream().collect(averagingLong(Dish::getCalories))).ifPresent(System.out::println); }输出结果:testAveragingLong 466.66666666666674、collectingAndThen(收集数据,处理数据),将搜集结果,再做处理。4.1、CollectingAndThen 求平均数后,拼接一句话 Optional.ofNullable(menu.stream().collect(Collectors.collectingAndThen(averagingInt(Dish::getCalories),a->"This is Calories eques = "+a))).ifPresent(System.out::println);输出结果:testCollectingAndThen This is Calories eques = 466.66666666666674.2、获取MEAT类,之后再往里面加入其它类型 List<Dish> collect = menu.stream().filter(m -> Dish.Type.MEAT.equals(m.getType())).collect(toList()); collect.add(new Dish("回锅肉", true, 550, Dish.Type.OTHER)); collect.stream().forEach(System.out::println);输出结果:Dish{name='pork', vegetarian=false, calories=800, type=MEAT} Dish{name='beef', vegetarian=false, calories=700, type=MEAT} Dish{name='chicken', vegetarian=false, calories=400, type=MEAT} Dish{name='回锅肉', vegetarian=true, calories=550, type=OTHER}4.3、CollectingAndThen 如果想将收集结果设置为不可修改 List<Dish> meatCollect = menu.stream().filter(m -> Dish.Type.MEAT.equals(m.getType())).collect(collectingAndThen(toList(), Collections::unmodifiableList)); //修改时就会报错:Exception in thread "main" java.lang.UnsupportedOperationException meatCollect.add(new Dish("回锅肉", true, 550, Dish.Type.OTHER)); collect.stream().forEach(System.out::println);输出结果:Exception in thread "main" java.lang.UnsupportedOperationException5、counting 统计 返回Long类型 public static void testCounting(){ System.out.println("testCounting"); Optional.ofNullable(menu.stream().collect(Collectors.counting())).ifPresent(System.out::println); }输出结果:testCounting 96、groupingBy 分组public static void testGroupingByFunction(){ System.out.println("testGroupingByFunction"); Optional.of(menu.stream().collect(Collectors.groupingBy(Dish::getType))).ifPresent(System.out::println); }输出结果:testGroupingByFunction {OTHER=[Dish{name='french fries', vegetarian=true, calories=530, type=OTHER}, Dish{name='rice', vegetarian=true, calories=350, type=OTHER}, Dish{name='season fruit', vegetarian=true, calories=120, type=OTHER}, Dish{name='pizza', vegetarian=true, calories=550, type=OTHER}], MEAT=[Dish{name='pork', vegetarian=false, calories=800, type=MEAT}, Dish{name='beef', vegetarian=false, calories=700, type=MEAT}, Dish{name='chicken', vegetarian=false, calories=400, type=MEAT}], FISH=[Dish{name='prawns', vegetarian=false, calories=300, type=FISH}, Dish{name='salmon', vegetarian=false, calories=450, type=FISH}]} 7、groupingBy 分组后统计 public static void testGroupingByFunctionAndCollector(){ System.out.println("testGroupingByFunctionAndCollector"); Optional.of(menu.stream().collect(Collectors.groupingBy(Dish::getType,counting()))).ifPresent(System.out::println); }输出结果:testGroupingByFunctionAndCollector {OTHER=4, MEAT=3, FISH=2}8、groupingBy 分组后求平均值,默认是HashMap,通过groupingBy修改返回类型 public static void testGroupingByFunctionAndSuppilerAndCollector(){ System.out.println("testGroupingByFunctionAndSuppilerAndCollector"); Map<Dish.Type, Double> map = Optional.of(menu.stream().collect(groupingBy(Dish::getType, averagingInt(Dish::getCalories)))).get(); //默认是返回HashMap类型 Optional.ofNullable(map.getClass()).ifPresent(System.out::println); TreeMap<Dish.Type, Double> newMap = Optional.of(menu.stream().collect(groupingBy(Dish::getType, TreeMap::new, averagingInt(Dish::getCalories)))).get(); //groupingBy:修改返回类型为TreeMap Optional.ofNullable(newMap.getClass()).ifPresent(System.out::println); }输出结果:testGroupingByFunctionAndSuppilerAndCollector class java.util.HashMap class java.util.TreeMap