搜索到
53
篇与
的结果
-
 线程按序交替 线程按序交替package com.yanxizhu; import java.util.concurrent.locks.Condition; import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReentrantLock; /** * @description: 线程按序交替 * @date: 2022/3/19 14:47 * @version: 1.0 */ public class PrintInfo { public static void main(String[] args) { print print = new print(); new Thread(new Runnable() { @Override public void run() { for(int i=1;i<5;i++){ try { print.printA(i); } catch (InterruptedException e) { e.printStackTrace(); } } } },"A").start(); new Thread(new Runnable() { @Override public void run() { for(int i=1;i<5;i++){ try { print.printB(i); } catch (InterruptedException e) { e.printStackTrace(); } } } },"B").start(); new Thread(new Runnable() { @Override public void run() { for(int i=1;i<5;i++){ try { print.printC(i); } catch (InterruptedException e) { e.printStackTrace(); } } } },"C").start(); } } class print{ private int num =1; Lock lock = new ReentrantLock(); Condition condition1 = lock.newCondition(); Condition condition2 = lock.newCondition(); Condition condition3 = lock.newCondition(); public void printA(int i) throws InterruptedException { lock.lock(); try{ if(num != 1){ condition1.await(); } System.out.println("A=="+Thread.currentThread().getName()+"====i="+i); num=2; condition2.signal(); }finally { lock.unlock(); } } public void printB(int i) throws InterruptedException { lock.lock(); try{ if(num != 2){ condition2.await(); } System.out.println("B=="+Thread.currentThread().getName()+"====i="+i); num=3; condition3.signal(); }finally { lock.unlock(); } } public void printC(int i) throws InterruptedException { lock.lock(); try{ if(num != 3){ condition3.await(); } System.out.println("C=="+Thread.currentThread().getName()+"====i="+i); num=1; condition1.signal(); }finally { lock.unlock(); } } }打印结果:A==A====i=1 B==B====i=1 C==C====i=1 A==A====i=2 B==B====i=2 C==C====i=2 A==A====i=3 B==B====i=3 C==C====i=3 A==A====i=4 B==B====i=4 C==C====i=4
线程按序交替 线程按序交替package com.yanxizhu; import java.util.concurrent.locks.Condition; import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReentrantLock; /** * @description: 线程按序交替 * @date: 2022/3/19 14:47 * @version: 1.0 */ public class PrintInfo { public static void main(String[] args) { print print = new print(); new Thread(new Runnable() { @Override public void run() { for(int i=1;i<5;i++){ try { print.printA(i); } catch (InterruptedException e) { e.printStackTrace(); } } } },"A").start(); new Thread(new Runnable() { @Override public void run() { for(int i=1;i<5;i++){ try { print.printB(i); } catch (InterruptedException e) { e.printStackTrace(); } } } },"B").start(); new Thread(new Runnable() { @Override public void run() { for(int i=1;i<5;i++){ try { print.printC(i); } catch (InterruptedException e) { e.printStackTrace(); } } } },"C").start(); } } class print{ private int num =1; Lock lock = new ReentrantLock(); Condition condition1 = lock.newCondition(); Condition condition2 = lock.newCondition(); Condition condition3 = lock.newCondition(); public void printA(int i) throws InterruptedException { lock.lock(); try{ if(num != 1){ condition1.await(); } System.out.println("A=="+Thread.currentThread().getName()+"====i="+i); num=2; condition2.signal(); }finally { lock.unlock(); } } public void printB(int i) throws InterruptedException { lock.lock(); try{ if(num != 2){ condition2.await(); } System.out.println("B=="+Thread.currentThread().getName()+"====i="+i); num=3; condition3.signal(); }finally { lock.unlock(); } } public void printC(int i) throws InterruptedException { lock.lock(); try{ if(num != 3){ condition3.await(); } System.out.println("C=="+Thread.currentThread().getName()+"====i="+i); num=1; condition1.signal(); }finally { lock.unlock(); } } }打印结果:A==A====i=1 B==B====i=1 C==C====i=1 A==A====i=2 B==B====i=2 C==C====i=2 A==A====i=3 B==B====i=3 C==C====i=3 A==A====i=4 B==B====i=4 C==C====i=4 -
SpringBoot整合seata分布式事务(不适用高并发场景) Springboot整合seata分布式事务一、创建seata日志表-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log CREATE TABLE `undo_log` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20) NOT NULL, `xid` varchar(100) NOT NULL, `context` varchar(128) NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11) NOT NULL, `log_created` datetime NOT NULL, `log_modified` datetime NOT NULL, `ext` varchar(100) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;二、安装事务协调器(seata-server)1、下载地址 2、导入依赖<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-seata</artifactId> </dependency>3、启动seata服务器4、seata文件说明registry.conf:注册中心配置。这里执行注册中西为nacos。type = "nacos",config {执行seata配置数据放在那里,这里默认使用文件放配置数据。 type = "file"file.conf:seata默认配置信息存放这里。例如,事务日志存放地方配置## transaction log store, only used in server side store { ## store mode: file、db mode = "file" ## file store property file { ## store location dir dir = "sessionStore" # branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions maxBranchSessionSize = 16384 # globe session size , if exceeded throws exceptions maxGlobalSessionSize = 512 # file buffer size , if exceeded allocate new buffer fileWriteBufferCacheSize = 16384 # when recover batch read size sessionReloadReadSize = 100 # async, sync flushDiskMode = async } ## database store property db { ## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc. datasource = "druid" ## mysql/oracle/postgresql/h2/oceanbase etc. dbType = "mysql" driverClassName = "com.mysql.jdbc.Driver" ## if using mysql to store the data, recommend add rewriteBatchedStatements=true in jdbc connection param url = "jdbc:mysql://127.0.0.1:3306/seata?rewriteBatchedStatements=true" user = "mysql" password = "mysql" minConn = 5 maxConn = 30 globalTable = "global_table" branchTable = "branch_table" lockTable = "lock_table" queryLimit = 100 } }三、自定义代理数据源注意:所有想要用到分布式事务的微服务使用seata DataSourceProxy代理自己的数据源。springboot默认使用的是Hikari数据源。DataSourceAutoConfiguration.java源代码:// // Source code recreated from a .class file by IntelliJ IDEA // (powered by FernFlower decompiler) // package org.springframework.boot.autoconfigure.jdbc; import javax.sql.DataSource; import javax.sql.XADataSource; import org.springframework.boot.autoconfigure.condition.AnyNestedCondition; import org.springframework.boot.autoconfigure.condition.ConditionMessage; import org.springframework.boot.autoconfigure.condition.ConditionOutcome; import org.springframework.boot.autoconfigure.condition.ConditionalOnClass; import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean; import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty; import org.springframework.boot.autoconfigure.condition.SpringBootCondition; import org.springframework.boot.autoconfigure.condition.ConditionMessage.Builder; import org.springframework.boot.autoconfigure.jdbc.DataSourceConfiguration.Dbcp2; import org.springframework.boot.autoconfigure.jdbc.DataSourceConfiguration.Generic; import org.springframework.boot.autoconfigure.jdbc.DataSourceConfiguration.Hikari; import org.springframework.boot.autoconfigure.jdbc.DataSourceConfiguration.OracleUcp; import org.springframework.boot.autoconfigure.jdbc.DataSourceConfiguration.Tomcat; import org.springframework.boot.autoconfigure.jdbc.DataSourceInitializationConfiguration.InitializationSpecificCredentialsDataSourceInitializationConfiguration; import org.springframework.boot.autoconfigure.jdbc.DataSourceInitializationConfiguration.SharedCredentialsDataSourceInitializationConfiguration; import org.springframework.boot.autoconfigure.jdbc.metadata.DataSourcePoolMetadataProvidersConfiguration; import org.springframework.boot.context.properties.EnableConfigurationProperties; import org.springframework.boot.jdbc.DataSourceBuilder; import org.springframework.boot.jdbc.EmbeddedDatabaseConnection; import org.springframework.context.annotation.Condition; import org.springframework.context.annotation.ConditionContext; import org.springframework.context.annotation.Conditional; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.Import; import org.springframework.context.annotation.ConfigurationCondition.ConfigurationPhase; import org.springframework.core.env.Environment; import org.springframework.core.type.AnnotatedTypeMetadata; import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseType; import org.springframework.util.StringUtils; @Configuration( proxyBeanMethods = false ) @ConditionalOnClass({DataSource.class, EmbeddedDatabaseType.class}) @ConditionalOnMissingBean( type = {"io.r2dbc.spi.ConnectionFactory"} ) @EnableConfigurationProperties({DataSourceProperties.class}) @Import({DataSourcePoolMetadataProvidersConfiguration.class, InitializationSpecificCredentialsDataSourceInitializationConfiguration.class, SharedCredentialsDataSourceInitializationConfiguration.class}) public class DataSourceAutoConfiguration { public DataSourceAutoConfiguration() { } static class EmbeddedDatabaseCondition extends SpringBootCondition { private static final String DATASOURCE_URL_PROPERTY = "spring.datasource.url"; private final SpringBootCondition pooledCondition = new DataSourceAutoConfiguration.PooledDataSourceCondition(); EmbeddedDatabaseCondition() { } public ConditionOutcome getMatchOutcome(ConditionContext context, AnnotatedTypeMetadata metadata) { Builder message = ConditionMessage.forCondition("EmbeddedDataSource", new Object[0]); if (this.hasDataSourceUrlProperty(context)) { return ConditionOutcome.noMatch(message.because("spring.datasource.url is set")); } else if (this.anyMatches(context, metadata, new Condition[]{this.pooledCondition})) { return ConditionOutcome.noMatch(message.foundExactly("supported pooled data source")); } else { EmbeddedDatabaseType type = EmbeddedDatabaseConnection.get(context.getClassLoader()).getType(); return type == null ? ConditionOutcome.noMatch(message.didNotFind("embedded database").atAll()) : ConditionOutcome.match(message.found("embedded database").items(new Object[]{type})); } } private boolean hasDataSourceUrlProperty(ConditionContext context) { Environment environment = context.getEnvironment(); if (environment.containsProperty("spring.datasource.url")) { try { return StringUtils.hasText(environment.getProperty("spring.datasource.url")); } catch (IllegalArgumentException var4) { } } return false; } } static class PooledDataSourceAvailableCondition extends SpringBootCondition { PooledDataSourceAvailableCondition() { } public ConditionOutcome getMatchOutcome(ConditionContext context, AnnotatedTypeMetadata metadata) { Builder message = ConditionMessage.forCondition("PooledDataSource", new Object[0]); return DataSourceBuilder.findType(context.getClassLoader()) != null ? ConditionOutcome.match(message.foundExactly("supported DataSource")) : ConditionOutcome.noMatch(message.didNotFind("supported DataSource").atAll()); } } static class PooledDataSourceCondition extends AnyNestedCondition { PooledDataSourceCondition() { super(ConfigurationPhase.PARSE_CONFIGURATION); } @Conditional({DataSourceAutoConfiguration.PooledDataSourceAvailableCondition.class}) static class PooledDataSourceAvailable { PooledDataSourceAvailable() { } } @ConditionalOnProperty( prefix = "spring.datasource", name = {"type"} ) static class ExplicitType { ExplicitType() { } } } @Configuration( proxyBeanMethods = false ) @Conditional({DataSourceAutoConfiguration.PooledDataSourceCondition.class}) @ConditionalOnMissingBean({DataSource.class, XADataSource.class}) @Import({Hikari.class, Tomcat.class, Dbcp2.class, OracleUcp.class, Generic.class, DataSourceJmxConfiguration.class}) protected static class PooledDataSourceConfiguration { protected PooledDataSourceConfiguration() { } } @Configuration( proxyBeanMethods = false ) @Conditional({DataSourceAutoConfiguration.EmbeddedDatabaseCondition.class}) @ConditionalOnMissingBean({DataSource.class, XADataSource.class}) @Import({EmbeddedDataSourceConfiguration.class}) protected static class EmbeddedDatabaseConfiguration { protected EmbeddedDatabaseConfiguration() { } } } 导入很多数据源 @Import({Hikari.class, Tomcat.class, Dbcp2.class, OracleUcp.class, Generic.class, DataSourceJmxConfiguration.class})DataSourceConfiguration.java源代码@Configuration( proxyBeanMethods = false ) @ConditionalOnClass({HikariDataSource.class}) @ConditionalOnMissingBean({DataSource.class}) @ConditionalOnProperty( name = {"spring.datasource.type"}, havingValue = "com.zaxxer.hikari.HikariDataSource", matchIfMissing = true ) static class Hikari { Hikari() { } @Bean @ConfigurationProperties( prefix = "spring.datasource.hikari" ) HikariDataSource dataSource(DataSourceProperties properties) { HikariDataSource dataSource = (HikariDataSource)DataSourceConfiguration.createDataSource(properties, HikariDataSource.class); if (StringUtils.hasText(properties.getName())) { dataSource.setPoolName(properties.getName()); } return dataSource; } }自定义代理数据源配置:import com.zaxxer.hikari.HikariDataSource; import io.seata.rm.datasource.DataSourceProxy; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.autoconfigure.jdbc.DataSourceProperties; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.util.StringUtils; import javax.sql.DataSource; /** * @description: Seata自定义代理数据源 * @author: <a href="mailto:batis@foxmail.com">清风</a> * @date: 2022/3/12 14:41 * @version: 1.0 */ @Configuration public class MySeataConfig { @Autowired DataSourceProperties dataSourceProperties; @Bean public DataSource dataSource(DataSourceProperties dataSourceProperties){ HikariDataSource dataSource = dataSourceProperties.initializeDataSourceBuilder().type(HikariDataSource.class).build(); if (StringUtils.hasText(dataSourceProperties.getName())) { dataSource.setPoolName(dataSourceProperties.getName()); } return new DataSourceProxy(dataSource); } }四、复制seata配置文件到项目resources下主要复制seata里面的模板文件file.conf、registry.conf注意:file.conf 的 service.vgroup_mapping 配置必须和spring.application.name一致。vgroup_mapping.{应用名称}-fescar-service-group = "default"service{ vgroup_mapping.family-booking-fescar-service-group = "default" }family-booking:微服务名字也可以通过配置 spring.cloud.alibaba.seata.tx-service-group修改后缀,但是必须和file.conf中的配置保持一致五、使用在分布式事务入口方法加上全局事务注解@GlobalTransactional,远程调用方法上加本地事务注解@Transactional即可。@GlobalTransactional @Transactional public PageUtils queryPage(Map<String, Object> params) { //调用远程方法,另一个微服务的方法加上小事务@Transactional }六、使用场景不适用高并发的场景,适用普通的业务远程调用。seata默认是使用的AT模式。针对高并发场景还是的用柔性事务,消息队列、延迟队列,MQ中间件完成。
-
CompletableFuture异步编排 通过线程池性能稳定,也可以获取执行结果,并捕获异常。但是,在业务复杂情况下,一个异步调用可能会依赖于另一个异步调用的执行结果。因此我们可以使用completableFuture 异步编排方案。比如:一个业务场景,需要同时获取多个数据,如果同步线程挨个执行,则需要时间为所有线程执行时间的总和。如果我们使用异步线程执行,所需时间则为耗时最长那个异步线程的执行时间。如果多个异常线程之间还存在依赖关系,比如线程3需要线程1的执行结果,线程6依赖线程3、线程2,那这个问题怎么解决呢。那就可以使用completableFuture 异步编排方案实现。注意:completableFuture 是jdk1.8之后添加的一个功能。CompletableFuture接口:public class CompletableFuture<T> implements Future<T>, CompletionStage<T> {public interface Future<V> {以前用到的FutureTask就是用到的Future可以得到返回结果public class FutureTask<V> implements RunnableFuture<V> {public interface RunnableFuture<V> extends Runnable, Future<V> { /** * Sets this Future to the result of its computation * unless it has been cancelled. */ void run(); }Future可以得到返回结果CompletableFuture随便一个方法,都接受一个Function public <U> CompletableFuture<U> applyToEither( CompletionStage<? extends T> other, Function<? super T, U> fn) { return orApplyStage(null, other, fn); }@FunctionalInterface public interface Function<T, R> {Function是一个@FunctionalInterface,所以对Lambda使用要熟悉。CompletableFuture异步编排问题多个异步线程远程调用会导致丢失请求头,原因是多个线程,通过拦截器不能获取其它线程的请求的heard信息。解决方案:每个线程共享自己的requestAttributes。自定义feign拦截器:import feign.RequestInterceptor; import feign.RequestTemplate; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.web.context.request.RequestContextHolder; import org.springframework.web.context.request.ServletRequestAttributes; import javax.servlet.http.HttpServletRequest; /** * @description: TODO * @author: <a href="mailto:batis@foxmail.com">清风</a> * @date: 2022/3/10 23:03 * @version: 1.0 */ @Configuration public class FamilyFegin { @Bean(name ="requestInterceptor") public RequestInterceptor requestInterceptor(){ return new RequestInterceptor() { @Override public void apply(RequestTemplate requestTemplate) { //RequestContextHolder拿到刚请求来的数据 ServletRequestAttributes requestAttributes = (ServletRequestAttributes)RequestContextHolder.getRequestAttributes(); System.out.println("requestAttributes线程"+Thread.currentThread().getId()); HttpServletRequest request = requestAttributes.getRequest(); System.out.println("调用feign之前"); if(request != null){ //同步请求头数据 String cookie = request.getHeader("Cookie");//老数据 //给新请求同步老请求的cookie requestTemplate.header("Cookie", cookie); } } }; } }web配置:因为需要拦截器生效import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.servlet.config.annotation.InterceptorRegistry; import org.springframework.web.servlet.config.annotation.WebMvcConfigurer; /** * @description: WEB配置 * @author: <a href="mailto:batis@foxmail.com">清风</a> * @date: 2022/3/10 22:40 * @version: 1.0 */ public class FamilyWebConfig implements WebMvcConfigurer { @Autowired LoginUserInterceptor loginUserInterceptor; @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(loginUserInterceptor).addPathPatterns("/**"); } }CompletableFuture异步编排import org.springframework.web.context.request.RequestContextHolder; import org.springframework.web.context.request.ServletRequestAttributes; import java.util.concurrent.CompletableFuture; import java.util.concurrent.ExecutionException; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; /** * @description: CompletableFuture异步编排 * @author: <a href="mailto:batis@foxmail.com">清风</a> * @date: 2022/3/10 23:32 * @version: 1.0 */ public class MyCompletableFuture { public static ExecutorService executorService = Executors.newFixedThreadPool(10); public void myOpenFeign() throws ExecutionException, InterruptedException { System.out.println("主线程0"); //远程调用存在丢失请求头的问题,因为不在同一线程,导致自定义拦截器不能获取head信息。 //解决丢失请求头方案: ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes(); //第一个异步任务 CompletableFuture<Void> oneFuture = CompletableFuture.runAsync(() -> { System.out.println("辅线程1"); //每个线程都共享一下自己的requestAttributes RequestContextHolder.setRequestAttributes(requestAttributes); //异步线程远程调用,业务1 //异步线程调用业务代码 }, executorService); //第二个异步任务 CompletableFuture<Void> twoFuture = CompletableFuture.runAsync(() -> { System.out.println("辅线程2"); //每个线程都共享一下自己的requestAttributes RequestContextHolder.setRequestAttributes(requestAttributes); //异步线程远程调用,业务2 //异步线程调用业务代码 }, executorService); CompletableFuture.allOf(oneFuture, twoFuture).get(); } }以上就是解决CompletableFuture异步编排,异步多线程引起的远程调用请求丢失解决方案。代码中共享requestAttributes原因ThreadLocal数据:ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();RequestContextHolder主线程不一样获取的数据不一样,如下:import javax.faces.context.FacesContext; import org.springframework.core.NamedInheritableThreadLocal; import org.springframework.core.NamedThreadLocal; import org.springframework.lang.Nullable; import org.springframework.util.ClassUtils; public abstract class RequestContextHolder { private static final boolean jsfPresent = ClassUtils.isPresent("javax.faces.context.FacesContext", RequestContextHolder.class.getClassLoader()); private static final ThreadLocal<RequestAttributes> requestAttributesHolder = new NamedThreadLocal("Request attributes"); private static final ThreadLocal<RequestAttributes> inheritableRequestAttributesHolder = new NamedInheritableThreadLocal("Request context"); public RequestContextHolder() { }
-
Springboot拦截器配置 Springboot拦截器配置1、拦截器配置,主要实现HandlerInterceptor接口import org.springframework.stereotype.Component; import org.springframework.web.servlet.HandlerInterceptor; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; /** * @description: 拦截器,配合FamilyWebConfig 配置使用 * @author: <a href="mailto:batis@foxmail.com">清风</a> * @date: 2022/3/10 22:36 * @version: 1.0 */ @Component public class LoginUserInterceptor implements HandlerInterceptor { public static ThreadLocal<Object> objUser = new ThreadLocal<>(); @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { Object loginusr = request.getSession().getAttribute("LOGIN_USR"); if(loginusr != null){ objUser.set(loginusr); //登录了才能访问 return true; }else{ //没登录,跳转去登录 return false; } } } 由于拦截器需要配合web配置使用,因此创建web配置。2、web配置主要实现WebMvcConfigurer接口import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.servlet.config.annotation.InterceptorRegistry; import org.springframework.web.servlet.config.annotation.WebMvcConfigurer; /** * @description: WEB配置 * @author: <a href="mailto:batis@foxmail.com">清风</a> * @date: 2022/3/10 22:40 * @version: 1.0 */ public class FamilyWebConfig implements WebMvcConfigurer { @Autowired LoginUserInterceptor loginUserInterceptor; @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(loginUserInterceptor).addPathPatterns("/**"); } }
-
JAVA面向对象有那些特征 JAVA面向对象有那些特征?面向对象编程是利用类和对象编程的一种思想。万物可归类,类是对于世界事物的高度抽象,不同的事物之间有不同的关系,一个类自身与外界的封装关系,一个父类和子类的继承关系,一个类和多个类的多态关系。万物皆对象,对象是具体的世界事物,面向对象的三大特征封装,继承,多态。封装,封装说明一个类行为和属性与其他类的关系,低耦合,高内聚;继承是父类和子类的关系,多态说的是类与类的关系。封装隐藏了类的内部实现机制,可以在不影响使用的情况下改变类的内部结构,同时也保护了数据。对外界而已它的内部细节是隐藏的,暴露给外界的只是它的访问方法。属性的封装:使用者只能通过事先定制好的方法来访问数据,可以方便地加入逻辑控制,限制对属性的不合理操作;方法的封装:使用者按照既定的方式调用方法,不必关心方法的内部实现,便于使用;便于修改,增强代码的可维护性;继承是从已有的类中派生出新的类,新的类能吸收已有类的数据属性和行为,并能扩展新的能力。在本质上是特殊~一般的关系,即常说的is-a关系。子类继承父类,表明子类是一种特殊的父类,并且具有父类所不具有的一些属性或方法。从多种实现类中抽象出一个基类,使其具备多种实现类的共同特性,当实现类用extends关键字继承了基类(父类)后,实现类就具备了这些相同的属性。继承的类叫做子类(派生类或者超类),被继承的类叫做父类(或者基类)。比如从猫类、狗类、虎类中可以抽象出一个动物类,具有和猫、狗、虎类的共同特性(吃、跑、叫等)。Java通过extends关键字来实现继承,父类中通过private定义的变量和方法不会被继承,不能在子类中直接操作父类通过private定义的变量以及方法。继承避免了对一般类和特殊类之间共同特征进行的重复描述,通过继承可以清晰地表达每一项共同特征所适应的概念范围,在一般类中定义的属性和操作适应于这个类本身以及它以下的每一层特殊类的全部对象。运用继承原则使得系统模型比较简练也比较清晰。相比于封装和继承,Java多态是三大特性中比较难的一个,封装和继承最后归结于多态,多态指的是类和类的关系,两个类由继承关系,存在有方法的重写,故而可以在调用时有父类引用指向子类对象。多态必备三个要素:继承,重写,父类引用指向子类对象。继承、封装:增强了代码的可复用性,多态:增加了可移植性、健壮性、灵活性。
-
ArrayList和LinkedList的区别 ArrayList和LinkedList都实现了List接口,他们有以下的不同点:ArrayList是基于索引的数据接口,它的底层是数组。它可以以O(1)时间复杂度对元素进行随机访问。与此对应,LinkedList是以元素列表的形式存储它的数据,每一个元素都和它的前一个和后一个元素链接在一起,在这种情况下,查找某个元素的时间复杂度是O(n)。相对于ArrayList,LinkedList的插入,添加,删除操作速度更快,因为当元素被添加到集合任意位置的时候,不需要像数组那样重新计算大小或者是更新索引。LinkedListt比ArrayList更占内存,因为LinkedList为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素。也可以参考ArrayList vs.LinkedList。1)因为Array是基于索引(index)的数据结构,它使用索引在数组中搜索和读取数据是很快的。Array 获取数据的时间复杂度是O(1),但是要删除数据却是开销很大的,因为这需要重排数组中的所有数据。2)相对于Arraylist,LinkedList插入是更快的。因为LinkedList不像ArrayList一样,不需要改变数组的大小,也不需要在数组装满的时候要将所有的数据重新装入一个新的数组,这是ArrayList最坏的一种情况,时间复杂度是O(n),而LinkedList中插入或删除的时间复杂度仅为O(1)。ArrayList 在插入数据时还需要更新索引(除了插入数组的尾部)。3)类似于插入数据,删除数据时,LinkedList 也优于Arraylist。4)LinkedList 需要更多的内存,因为ArrayList的每个索引的位置是实际的数据,而LinkedList中的每个节点中存储的是实际的数据和前后节点的位置(一个LinkedList实例存储了两个值:Nodefirst和Nodelast分别表示链表的其实节点和尾节点,每个Node 实例存储了三个值:Eitem,Node next,Node pre)。什么场景下更适宜使用LinkedList,而不用ArrayList1)你的应用不会随机访问数据。因为如果你需要LinkedList中的第n个元素的时候,你需要从第一个元素顺序数到第n个数据,然后读取数据。2)你的应用更多的插入和删除元素,更少的读取数据。因为插入和删除元素不涉及重排数据,所以它要比ArrayList要快。
-
JAVA中抽象类和接口有什么区别 JAVA中抽象类和接口有什么区别?相同:1.不能够实例化2.可以将抽象类和接口类型作为引用类型3.一个类如果继承了某个抽象类或者实现了某个接口都需要对其中的抽象方法全部进行实现,否则该类仍然需要被声明为抽象类不同:抽象类:1.抽象类中可以定义构造器2.可以有抽象方法和具体方法3.接口中的成员全都是public的4.抽象类中可以定义成员变量5.有抽象方法的类必须被声明为抽象类,而抽象类未必要有抽象方法6.抽象类中可以包含静态方法7.一个类只能继承一个抽象类接口:1.接口中不能定义构造器2.方法全部都是抽象方法3.抽象类中的成员可以是private、默认、protected、public4.接口中定义的成员变量实际上都是常量5.接口中不能有静态方法6.一个类可以实现多个接口
-
JDK1.8新特性 JDK1.8的新特性一、接口的默认方法Java8允许我们给接口添加一个非抽象的方法实现,只需要使用default关键字即可,这个特征又叫做扩展方法,示例如下:代码如下:interface Formula{ double calculate(int a); default double sqrt(int a){ return Math.sqrt(a); } }Formula接口在拥有calculate方法之外同时还定义了sqrt方法,实现了Formula接口的子类只需要实现一个calculate方法,默认方法sqrt将在子类上可以直接使用。代码如下:Formula formula=new Formula){@Override public double calculate(int a){return sqrt(a100);}];formula.calculate(100);/100.0 formula.sqrt(16);//4.0文中的formula被实现为一个匿名类的实例,该代码非常容易理解,6行代码实现了计算sqrt(a*100)。在下一节中,我们将会看到实现单方法接口的更简单的做法。译者注:在Java中只有单继承,如果要让一个类赋予新的特性,通常是使用接口来实现,在C++中支持多继承,允许一个子类同时具有多个父类的接口与功能,在其他语言中,让一个类同时具有其他的可复用代码的方法叫做mixin。新的Java8的这个特新在编译器实现的角度上来说更加接近Scala的trait。在C#中也有名为扩展方法的概念,允许给已存在的类型扩展方法,Java8的这个在语义上有差别。二、Lambda表达式首先看看在老版本的Java中是如何排列字符串的:代码如下:List names=Arrays.asList("peterF","anna","mike","xenia");Collections.sort(names,new Comparator){@Override public int compare(String a,String b){return b.compareTo(a);}});只需要给静态方法Collections.sort传入一个List对象以及一个比较器来按指定顺序排列。通常做法都是创建一个匿名的比较器对象然后将其传递给sort方法。在Java8中你就没必要使用这种传统的匿名对象的方式了,Java8提供了更简洁的语法,lambda表达式:代码如下:Collections.sort(names,(String a,String b)->{return b.compareTo(a);});看到了吧,代码变得更段且更具有可读性,但是实际上还可以写得更短:代码如下:Collections.sort(names,(String a,String b)->b.compareTo(a);对于函数体只有一行代码的,你可以去掉大括号0以及return关键字,但是你还可以写得更短点:代码如下:Collections.sort(names,(a,b)>b.compareTo(a);Java编译器可以自动推导出参数类型,所以你可以不用再写一次类型。接下来我们看看lambda表达式还能作出什么更方便的东西来:三、函数式接口Lambda表达式是如何在java的类型系统中表示的呢?每一个lambda表达式都对应一个类型,通常是接口类型。而“函数式接口”是指仅仅只包含一个抽象方法的接口,每一个该类型的lambda表达式都会被匹配到这个抽象方法。因为默认方法不算抽象方法,所以你也可以给你的函数式接口添加默认方法。我们可以将lambda表达式当作任意只包含一个抽象方法的接口类型,确保你的接口一定达到这个要求,你只需要给你的接口添加@Functionallnterface注解,编译器如果发现你标注了这个注解的接口有多于一个抽象方法的时候会报错的。示例如下:代码如下:@Functionallnterface interface Converter<F,T>{T convert(F from);}Converter<String,Integer>converter=from)->Integer.valueOf(from);Integer converted=converter.convert("123");System.out.printin(converted);//123需要注意如果@Functionallnterface如果没有指定,上面的代码也是对的。译者注将lambda表达式映射到一个单方法的接口上,这种做法在Java8之前就有别的语言实现,比如Rhino JavaScript解释器,如果一个函数参数接收一个单方法的接口而你传递的是一个function,Rhino 解释器会自动做一个单接口的实例到function的适配器,典型的应用场景有 org.w3c.dom.events.EventTarget的addEventListener 第二个参数EventListener。四、方法与构造函数引用前一节中的代码还可以通过静态方法引用来表示:代码如下:Converter<String,Integer>converter=Integer:valueOf;Integer converted=converter.convert("123");System.out.printin(converted);//123Java8允许你使用:关键字来传递方法或者构造函数引用,上面的代码展示了如何引用一个静态方法,我们也可以引用一个对象的方法:代码如下:converter=something::startsWith;String converted=converter.convert("Java");System.out.printin(converted);//"接下来看看构造函数是如何使用:关键字来引用的,首先我们定义一个包含多个构造函数的简单类:代码如下:代码如下:Converter<String,Integer> converter=Integer::valueOf;Integer converted=converter.convert("123");System.out.println(converted);//123Java8允许你使用::关键字来传递方法或者构造函数引用,上面的代码展示了如何引用一个静态方法,我们也可以引用一个对象的方法:代码如下:converter=something:startsWith;String converted=converter.convert("Java");system.out.println(converted);/∥"y"接下来看看构造函数是如何使用:关键字来引用的,首先我们定义一个包含多个构造函数的简单类:代码如下:class Person{String firstName;String lastName;Person)}Person(String firstName,String lastName){this.firstName =firstName;this.lastName=lastName;}}接下来我们指定一个用来创建Person对象的对象工厂接口:代码如下:interface PersonFactory{P create(String firstName,String lastName);}这里我们使用构造函数引用来将他们关联起来,而不是实现一个完整的工厂:代码如下:PersonFactorypersonFactory=Person::new;Person person=personFactory.create("Peter","Parker");我们只需要使用Person::new来获取Person类构造函数的引用,Java编译器会自动根据PersonFactory.create方法的签名来选择合适的构造函数。五、Lambda作用域在lambda表达式中访问外层作用域和老版本的匿名对象中的方式很相似。你可以直接访问标记了final的外层局部变量,或者实例的字段以及静态变量。六、访问局部变量我们可以直接在lambda表达式中访问外层的局部变量:代码如下:final int num=1;Converter<Integer,String>stringConverter=(from)->String.valueof(from +num);stringConverter.convert(2);//3但是和匿名对象不同的是,这里的变量num可以不用声明为final,该代码同样正确:代码如下:int num=1;Converter<Integer,String>stringConverter=(from)->String.valueof(from+num);stringConverter.conver(2);//3不过这里的num必须不可被后面的代码修改(即隐性的具有fina的语义),例如下面的就无法编译:代码如下:int num=1;Converter<Integer,String>stringConverter =(from)->string.valueof(from +num);num=3;在lambda表达式中试图修改num同样是不允许的。七、访问对象字段与静态变量和本地变量不同的是,lambda内部对于实例的字段以及静态变量是即可读又可写。该行为和匿名对象是一致的:代码如下:class Lambda4{static int outerStaticNum;int outerNum;void testScopes(){Converter<Integer,String>stringConverter1=(from)->{outerNum=23;return String.valueof(from);};Converter<Integer,String>stringConverter2=(from)->{outerStaticNum=72;return String.valueof(from);};}}八、访问接口的默认方法还记得第一节中的formula例子么,接口Formula定义了一个默认方法sqrt可以直接被formula的实例包括匿名对象访问到,但是在lambda表达式中这个是不行的。Lambda表达式中是无法访问到默认方法的,以下代码将无法编译:代码如下:Formula formula=(a)->sqrt(a*100);Built-in Functional InterfacesJDK 1.8API包含了很多内建的函数式接口,在老Java中常用到的比如Comparator或者Runnable接口,这些接口都增加了@Functionallnterface注解以便能用在lambda上。Java8APl同样还提供了很多全新的函数式接口来让工作更加方便,有一些接口是来自Google Guava库里的,即便你对这些很熟悉了,还是有必要看看这些是如何扩展到lambda上使用的。Predicate接口Predicate 接口只有一个参数,返回boolean类型。该接口包含多种默认方法来将Predicate组合成其他复杂的逻辑(比如:与,或,非):代码如下:Predicatepredicate=(s)->s.length()>0;predicate.test("foo");//true predicate.negate().test("foo");//false Predicate nonNull =Objects:nonNull;PredicateisNull=Objects:isNull;PredicateisEmpty=String:isEmpty;PredicateisNotEmpty=isEmpty.negate();Function接口Function 接口有一个参数并且返回一个结果,并附带了一些可以和其他函数组合的默认方法(compose,andThen):代码如下:Function<String,Integer> tolnteger=Integer:valueOf;Function<String,String>backToString=tolnteger.andThen(String:valueOf);backToString.apply("123");//"123"Supplier 接口Supplier 接口返回一个任意范型的值,和Function接口不同的是该接口没有任何参数代码如下:Supplier personSupplier=Person:new;personSupplier get();//new PersonConsumer 接口Consumer接口表示执行在单个参数上的操作。代码如下:Consumergreeter=(p)->System.out.println("Hello,"+p.firstName);greeter.accept(new Person("Luke","Skywalker"));Comparator 接口Comparator是老ava中的经典接口,Java8在此之上添加了多种默认方法:代码如下:Comparatorcomparator =(p1,p2)->p1.firstName.compareTo(p2.firstName);Person p1=new Person("John","Doe");Person p2=new Person("Alice","Wonderland");comparator.compare(p1,p2);//>0 comparator.reversed().compare(p1,p2);//<0optional接口Optional 不是函数是接口,这是个用来防止NullPointerException异常的辅助类型,这是下一届中将要用到的重要概念,现在先简单的看看这个接口能干什么:Optional被定义为一个简单的容器,其值可能是null或者不是null。在Java8之前一般某个函数应该返回非空对象但是偶尔却可能返回了null,而在Java8中,不推荐你返回null而是返回Optional。代码如下:Optionaloptional=Optional.of("bam");optional.isPresent();//true optional.get();//"bam"optional.orElse("fallback");//"bam"optional.ifPresent((s)->System.out.println(s.charAt(O));//"b"Stream接口java.util.Stream 表示能应用在一组元素上一次执行的操作序列。Stream操作分为中间操作或者最终操作两种,最终操作返回一特定类型的计算结果,而中间操作返回Stream本身,这样你就可以将多个操作依次串起来。Stream 的创建需要指定一个数据源,比如java.util.Collection的子类,List或者Set,Map不支持。Stream的操作可以串行执行或者并行执行。首先看看Stream是怎么用,首先创建实例代码的用到的数据List:代码如下:List stringCollection=new ArrayList<>();;stringCollection.add("ddd2");stringCollection.add("aaa2");stringCollection.add("bbb1");stringCollection.add("aaa1");stringCollection.add("bbb3");stringCollection.add("ccc");stringCollection.add("bbb2");stringCollection.add("ddd1");Java 8扩展了集合类,可以通过Collection.stream()或者Collection.parallelStream()来创建一个Stream。下面几节将详细解释常用的Stream操作:Filter 过滤过滤通过一个predicate接口来过滤并只保留符合条件的元素,该操作属于中间操作,所以我们可以在过滤后的结果来应用其他Stream操作(比如forEach)。forEach需要一个函数来对过滤后的元素依次执行。forEach是一个最终操作,所以我们不能在forEach之后来执行其他Stream操作。代码如下:stringCollection.stream().filter(s)->s.startsWith("a").forEach(System.out::println);//"aaa2","aaal"Sort 排序排序是一个中间操作,返回的是排序好后的Stream。如果你不指定一个自定义的Comparator则会使用默认排序。代码如下:stringCollection.stream().sorted().filter(s)->s.startsWith("a")).forEach(System.out:printin);//"aaa1","aaa2"需要注意的是,排序只创建了一个排列好后的Stream,而不会影响原有的数据源,排序之后原数据stringCollection是不会被修改的:代码如下:System.out.printin(stringCollection);//ddd2,aaa2,bbb1,aaal,bbb3,ccc,bbb2,ddd1Map映射中间操作map会将元素根据指定的Function接口来依次将元素转成另外的对象,下面的示例展示了将字符串转换为大写字符串。你也可以通过map来讲对象转换成其他类型,map返回的Stream类型是根据你map传递进去的函数的返回值决定的。代码如下:stringCollection.stream().map(String:toUpperCase).sorted(a,b)->b.compareTo(a)).forEach(System.out:printin);//"DDD2","DDD1","CCC","BBB3","BBB2","AAA2","AAA1"Map映射中间操作map会将元素根据指定的Function接口来依次将元素转成另外的对象,下面的示例展示了将字符串转换为大写字符串。你也可以通过map来讲对象转换成其他类型,map返回的Stream类型是根据你map传递进去的函数的返回值决定的。代码如下:stringCollection.stream().map(String:toUpperCase).sorted((a,b)->b.compareTo(a)).forEach(System.out:printin);//"DDD2","DDD1","CCC","BBB3","BBB2","AAA2","AAA1"Match 匹配Stream提供了多种匹配操作,允许检测指定的Predicate是否匹配整个Stream。所有的匹配操作都是最终操作,并返回一个boolean类型的值。代码如下:boolean anyStartsWithA=stringCollection.stream().anyMatch(s)->s.startsWith("a");System.out.printin(anystartsWithA);/∥true boolean allStartsWithA=stringCollection.stream().allMatch(s)->s.startsWith("a"));System.out.printin(allStartsWithA);//false boolean noneStartsWithZ=stringCollection.stream().noneMatch(s)->s.startsWith("z");System.out.printin(noneStartsWithZ);//trueCount计数计数是一个最终操作,返回Stream中元素的个数,返回值类型是long。代码如下:long startsWithB=stringCollection.stream().filter((s)->s.startsWith("b")).count();System.out.printin(startsWithB);//3Reduce规约这是一个最终操作,允许通过指定的函数来讲stream中的多个元素规约为一个元素,规越后的结果是通过Optional接口表示的:代码如下:Optional reduced=stringCollection.stream().sorted).reduce((51,52)->51+"#"+52);reduced.ifPresent(System.out::println);//"aaal#aaa2#bbb1#bbb2#bbb3#cCC#ddd1#ddd2"并行Streams前面提到过Stream有串行和并行两种,串行Stream上的操作是在一个线程中依次完成,而并行Stream则是在多个线程上同时执行。下面的例子展示了是如何通过并行Stream来提升性能:首先我们创建一个没有重复元素的大表:代码如下:int max=1000000; List values=new Arraylist<>(max); for(inti=0;i< max;i++){ UUID uuid=UUID. randomUUID(); values. add(uuid. toString());}然后我们计算一下排序这个Stream要耗时多久,串行排序:代码如下:long to=System. nanoTime(); long count=values. stream(). sorted(). count(); System. out. println(count); long t1=System. nanoTime(); long millis =TimeUnit. NANOSECONDS. toMillis(t1-to); System. out. println(String. format("sequential sort took:%d ms", millis);∥串行耗时:899ms并行排序:代码如下:long to=System.nanoTime();long count=values.parallelStream().sorted).count();System.out.println(count);long t1=System.nanoTime();long mills=TimeUnit.NANOSECONDS.toMillis(t1-to);System.out.printin(String.format("parallel sort took:%d ms",millis));//并行排序耗时:472ms上面两个代码几乎是一样的,但是并行版的快了50%之多,唯一需要做的改动就是将stream()改为parallelStream()。Map前面提到过,Map类型不支持stream,不过Map提供了一些新的有用的方法来处理一些日常任务。代码如下:Map<Integer,String>map=new HashMap<>);for(inti=0;i<10;i++){map.putlfAbsent(i,"val"+i);}map.forEach(id,val)>System.out.println(val);以上代码很容易理解,putlfAbsent不需要我们做额外的存在性检查,而forEach则接收一个Consumer接口来对map里的每一个键值对进行操作。下面的例子展示了map上的其他有用的函数:代码如下:map. computelfPresent(3,(num, val)->val+num); map. get(3);//val33map. computelfPresent(9,(num, val)->nul); map. containsKey(9);//falsemap. computelfAbsent(23, num->"val"+num); map. containsKey(23);//true map. computelfAbsent(3, num->"bam"); map. get(3);//val33接下来展示如何在Map里删除一个键值全都匹配的项:代码如下:map.remove(3,"val3");map.get(3);//val33map.remove(3,"val33");map.get(3);/∥null另外一个有用的方法:代码如下:map.getOrDefault(42,"not found");//not found对Map的元素做合并也变得很容易了:代码如下:map.getOrDefault(42,"not found");//not found对Map的元素做合并也变得很容易了:代码如下:map.merge(9,"val9",(value,newValue)->value.concat(newValue));map.get(9);//val9map.merge(9,"concat",(value,newValue)->value.concat(newValue);map.get(9);//val9concat Merge做的事情是如果键名不存在则插入,否则则对原键对应的值做合并操作并重新插入到map中。九、Date API Java 8在包java.time下包含了一组全新的时间日期APl。新的日期APl和开源Joda-Time库差不多,但又不完全一样,下面的例子展示了这组新APl里最重要的一些部分:Clock时钟Clock类提供了访问当前日期和时间的方法,Clock是时区敏感的,可以用来取代System.currentTimeMils0来获取当前的微秒数。某一个特定的时间点也可以使用Instant类来表示,Instant类也可以用来创建老的java.util.Date对象。代码如下:Clock clock=Clock.systemDefaultZone();long millis =clock.mils();Instant instant=clock.instant();Date legacyDate=Date.from(instant);//legacy java.util.DateTimezones时区在新API中时区使用Zoneld来表示。时区可以很方便的使用静态方法of来获取到。时区定义了到UTS时间的时间差,在Instant时间点对象到本地日期对象之间转换的时候是极其重要的。代码如下:System.out.println(Zoneld.getAvailableZonelds());//prints all available timezone ids Zoneld zone1=Zoneld.of("Europe/Berlin");Zoneld zone2=Zoneld.of("Brazil/East");System.out.println(zone1.getRules();System.out.printin(zone2.getRules());LocalTime本地时间LocalTime 定义了一个没有时区信息的时间,例如晚上10点,或者17:30:15。下面的例子使用前面代码创建的时区创建了两个本地时间。之后比较时间并以小时和分钟为单位计算两个时间的时间差:代码如下:LocalTime now1=LocalTime.now(zone1);LocalTime now2=LocalTime.now(zone2);System.out.println(now1.isBefore(now2);//false long hoursBetween=ChronoUnit.HOURS.between(now1,now2);long minutesBetween=ChronoUnit.MINUTES.between(now1,now2);System.out.println(hoursBetween);//-3 System.out.printin(minutesBetween);//-239LocalTime 提供了多种工厂方法来简化对象的创建,包括解析时间字符串。代码如下:LocalTime late =LocalTime.of(23,59,59);System.out.println(late);//23:59:59DateTimeFormatter germanFormatter=Date TimeFormatter.ofLocalizedTime(FormatStyle.SHORT).withLocale(Locale.GERMAN);LocalTime leetTime=LocalTime.parse("13:37",germanFormatter);System.out.printin(leetTime);//13:37LocalDate本地日期LocalDate表示了一个确切的日期,比如2014-03-11。该对象值是不可变的,用起来和LocalTime基本一致。下面的例子展示了如何给Date对象加减天/月/年。另外要注意的是这些对象是不可变的,操作返回的总是一个新实例。代码如下:LocalDate today=LocalDate.now();LocalDate tomorrow =today.plus(1,Chronounit.DAYS);LocalDate yesterday=tomorrow.minusDays(2);LocalDate independenceDay =LocalDate.of(2014,Month.JULY,4);DayofWeek dayofweek=independenceDay.getDayOfWeek();System.out.printin(dayofWeek);//FRIDAY 从字符串解析一个LocalDate类型和解析LocalTime一样简单:代码如下:DateTimeFormatter germanFormatter=Date TimeFormatter.ofLocalizedDate(FormatStyle.MEDIUM).withLocale(Locale.GERMAN);LocalDate xmas =LocalDate.parse("24.12.2014",germanFormatter);System.out.println(xmas);//2014-12-24LocalDateTime 本地日期时间LocalDateTime同时表示了时间和日期,相当于前两节内容合并到一个对象上了。LocalDateTime和LocalTime还有LocalDate一样,都是不可变的。LocalDateTime提供了一些能访问具体字段的方法。代码如下:LocalDate Time sylvester=LocalDate Time.of(2014,Month.DECEMBER,31,23,59,59);DayofWeek dayofWeek=sylvester.getDayofWeek();System.out.println(dayOfWeek);//WEDNESDAY Month month=sylvester.getMonth();System.out.println(month);//DECEMBER long minuteOfDay=sylvester getLong(ChronoField.MINUTE_OF_DAY);System.out.println(minuteOfDay);//1439只要附加上时区信息,就可以将其转换为一个时间点Instant对象,Instant时间点对象可以很容易的转换为老式的java.util.Date。代码如下:Instant instant=sylvester.atZone(Zoneld.systemDefault().tolnstant();Date legacyDate=Date.from(instant);System.out.printin(legacyDate);//Wed Dec 31 23:59:59 CET 2014格式化LocalDateTime和格式化时间和日期一样的,除了使用预定义好的格式外,我们也可以自己定义格式:代码如下:DateTimeFormatter formatter=DateTimeFormatter.ofPattern("MMM dd,yyyy-HH:mm");LocalDateTime parsed=LocalDateTime.parse("Nov 03,2014-07:13",formatter);String string=formatter.format(parsed);System.out.println(string);//Nov 03,2014-07:13和java.text.NumberFormat不一样的是新版的DateTimeFormatter是不可变的,所以它是线程安全的。十、Annotation 注解在Java8中支持多重注解了,先看个例子来理解一下是什么意思。首先定义一个包装类Hints注解用来放置一组具体的Hint注解:代码如下:@interface Hints{Hint]value();}@Repeatable(Hints.class)@interface Hint{String value();}Java8允许我们把同一个类型的注解使用多次,只需要给该注解标注一下@Repeatable即可。例1:使用包装类当容器来存多个注解(老方法)代码如下:@Hints({@Hint("hint1"),@Hint("hint2")})class Person}例2:使用多重注解(新方法)代码如下:@Hint("hint1")@Hint("hint2")class Person}第二个例子里java编译器会隐性的帮你定义好@Hints注解,了解这一点有助于你用反射来获取这些信息:代码如下:Hint hint=Person. class. getAnnotation(Hint. class); System. out. println(hint);//null Hints hints1=Person. class. getAnnotation(Hints. class); System. out. printin(hints1. value(). length);//2Hint[]hints2=Person.class.getAnnotationsBy Type(Hint.class);System.out.printin(hints2.length);//2即便我们没有在Person类上定义@Hints注解,我们还是可以通过 getAnnotation(Hints.class)来获取@Hints注解,更加方便的方法是使用getAnnotationsBy Type 可以直接获取到所有的@Hint注解。另外ava8的注解还增加到两种新的target上了:代码如下:@Target{ElementType.TYPE_PARAMETER,ElementType.TYPE_USE})@interface MyAnnotation}关于Java8的新特性就写到这了,肯定还有更多的特性等待发掘。JDK1.8里还有很多很有用的东西,比如Arrays.parallelSort,StampedLock和CompletableFuture等等。
-
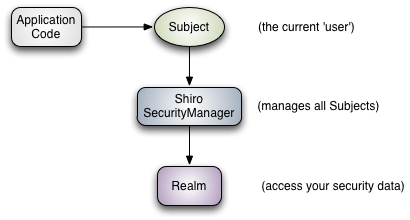
Shiro权限管理框架 首先知道Shiro架构有3个主要概念:Subject、SecurityManager和Realms。 Shiro基础架构图 : 基础架构说明:Subject: As we’ve mentioned in our Tutorial, the Subject is essentially a security specific ‘view’ of the the currently executing user. Whereas the word ‘User’ often implies a human being, a Subject can be a person, but it could also represent a 3rd-party service, daemon account, cron job, or anything similar - basically anything that is currently interacting with the software.Subject instances are all bound to (and require) a SecurityManager. When you interact with a Subject, those interactions translate to subject-specific interactions with the SecurityManager.(大概意思:Subject一词是一个安全术语,其基本意思是“当前的操作用户”。称之为“用户”并不准确,因为“用户”一词通常跟人相关。在安全领域,术语“Subject”可以是人,也可以是第三方进程、后台帐户(Daemon Account)、定时作业(Corn Job)或其他类似事物。它仅仅意味着“当前跟软件交互的东西”。但考虑到大多数目的和用途,你可以把它认为是Shiro的“用户”概念。在程序中你都能轻易的获得Subject,允许在任何需要的地方进行安全操作。每个Subject对象都必须与一个SecurityManager进行绑定,你访问Subject对象其实都是在与SecurityManager里的特定Subject进行交互。)SecurityManager: The SecurityManager is the heart of Shiro’s architecture and acts as a sort of ’umbrella’ object that coordinates its internal security components that together form an object graph. However, once the SecurityManager and its internal object graph is configured for an application, it is usually left alone and application developers spend almost all of their time with the Subject API.We will talk about the SecurityManager in detail later on, but it is important to realize that when you interact with a Subject, it is really the SecurityManager behind the scenes that does all the heavy lifting for any Subject security operation. This is reflected in the basic flow diagram above.(大概意思:Subject的“幕后”推手是SecurityManager。Subject代表了当前用户的安全操作,SecurityManager则管理所有用户的安全操作。它是Shiro框架的核心,充当“保护伞”,引用了多个内部嵌套安全组件,它们形成了对象图。但是,一旦SecurityManager及其内部对象图配置好,它就会退居幕后,应用开发人员几乎把他们的所有时间都花在Subject API调用上。那么,如何设置SecurityManager呢?嗯,这要看应用的环境。例如,Web应用通常会在Web.xml中指定一个Shiro Servlet Filter,这会创建SecurityManager实例,如果你运行的是一个独立应用,你需要用其他配置方式,但有很多配置选项。一个应用几乎总是只有一个SecurityManager实例。它实际是应用的Singleton(尽管不必是一个静态Singleton)。跟Shiro里的几乎所有组件一样,SecurityManager的缺省实现是POJO,而且可用POJO兼容的任何配置机制进行配置 - 普通的Java代码、Spring XML、YAML、.properties和.ini文件等。基本来讲,能够实例化类和调用JavaBean兼容方法的任何配置形式都可使用。)Realms: Realms act as the ‘bridge’ or ‘connector’ between Shiro and your application’s security data. When it comes time to actually interact with security-related data like user accounts to perform authentication (login) and authorization (access control), Shiro looks up many of these things from one or more Realms configured for an application.In this sense a Realm is essentially a security-specific DAO: it encapsulates connection details for data sources and makes the associated data available to Shiro as needed. When configuring Shiro, you must specify at least one Realm to use for authentication and/or authorization. The SecurityManager may be configured with multiple Realms, but at least one is required.(大概意思:Shiro的第三个也是最后一个概念是Realm。Realm充当了Shiro与应用安全数据间的“桥梁”或者“连接器”。也就是说,当与像用户帐户这类安全相关数据进行交互,执行认证(登录)和授权(访问控制)时,Shiro会从应用配置的Realm中查找很多内容。从这个意义上讲,Realm实质上是一个安全相关的DAO:它封装了数据源的连接细节,并在需要时将相关数据提供给Shiro。当配置Shiro时,你必须至少指定一个Realm,用于认证和(或)授权。配置多个Realm是可以的,但是至少需要一个。Shiro内置了可以连接大量安全数据源(又名目录)的Realm,如LDAP、关系数据库(JDBC)、类似INI的文本配置资源以及属性文件 等。如果缺省的Realm不能满足需求,你还可以插入代表自定义数据源的自己的Realm实现。象其他内部组件一样,由SecurityManager来管理如何使用Realms来获取安全的身份数据。)看了上面一大段介绍后肯定还不知道怎么回事,来个简单比喻吧: 比如:新到一家公司,网管给你一台开发机,一个账号密码(这对应账号密码),你此时不知道账号是属于什么角色,是超级管理员,还是普通账号(这里就是对应角色),如果是超级管理员那权限就比较打了,比如设置一张自己喜欢的桌面壁纸,如果是普通用户那就没有这个权限了,因为公司统一宣传公司形象,使用统一公司宣传桌面壁纸(这里对应权限也就是资源), 重点 ,网管给的账号密码是属于那个角色,拥有什么权限,不用我自己去判断,而是交给了电脑自己去判断,不用麻烦自己了。这里的账号密码也就类似上面的Subject,而电脑操作系统就类似SecurityManager,电脑操作系统怎么判断属于那个角色,有哪些权限,这个判断的逻辑就类似Realms。以后我们使用Shrio就主要就是SecurityManager中的Realms要我们 自己去实现自己的方法 ,比如这个账号有哪些对应的角色、有哪些权限。在用账号密码进行登录操作系统,这个过程就类似 认证 的过程,如果认证失败(账号或面错误登录失败)就返回提示信息登录失败,如果认证成功了,就把这个Subject(账号)对应的角色、权限一起返回给操作系统,登录成功后通过账号查找对应的角色、权限,并返回给操作系统的过程就类似 授权 了。最后我们就可以操作电脑, 判断 是超级管理还是普通用户了, 看看 有没有权限换壁纸了。到这里也许你大概明白了大体怎么回事,接下来我们就要看看Shiro的完整架构图,类似看看这个操作系统里面是怎么回事,有哪些东西,来实现认证、授权的。 Shiro核心架构图 : 核心架构说明:Subject (org.apache.shiro.subject.Subject)A security-specific ‘view’ of the entity (user, 3rd-party service, cron job, etc) currently interacting with the software.(当前与软件交互的实体(用户、第 3 方服务、cron 作业等)的特定于安全的“视图”。)SecurityManager (org.apache.shiro.mgt.SecurityManager)As mentioned above, the SecurityManager is the heart of Shiro’s architecture. It is mostly an ‘umbrella’ object that coordinates its managed components to ensure they work smoothly together. It also manages Shiro’s view of every application user, so it knows how to perform security operations per user.(如上所述,这SecurityManager是 Shiro 架构的核心。它主要是一个“伞”对象,用于协调其托管组件以确保它们一起顺利工作。它还管理 Shiro 对每个应用程序用户的视图,因此它知道如何为每个用户执行安全操作。)Authenticator (org.apache.shiro.authc.Authenticator)The Authenticator is the component that is responsible for executing and reacting to authentication (log-in) attempts by users. When a user tries to log-in, that logic is executed by the Authenticator. The Authenticator knows how to coordinate with one or more Realms that store relevant user/account information. The data obtained from these Realms is used to verify the user’s identity to guarantee the user really is who they say they are.(身份认证/登录,验证用户是不是拥有相应的身份,例如账号密码登陆)Authentication Strategy (org.apache.shiro.authc.pam.AuthenticationStrategy)If more than one Realm is configured, the AuthenticationStrategy will coordinate the Realms to determine the conditions under which an authentication attempt succeeds or fails (for example, if one realm succeeds but others fail, is the attempt successful? Must all realms succeed? Only the first?).(认证器,负责主体认证的,这是一个扩展点,如果用户觉得Shiro默认的不好,可以自定义实现;其需要认证策略(Authentication Strategy),即什么情况下算用户认证通过了;)Authorizer (org.apache.shiro.authz.Authorizer)The Authorizer is the component responsible determining users’ access control in the application. It is the mechanism that ultimately says if a user is allowed to do something or not. Like the Authenticator, the Authorizer also knows how to coordinate with multiple back-end data sources to access role and permission information. The Authorizer uses this information to determine exactly if a user is allowed to perform a given action.(Authorizer是部件负责确定用户在该应用程序的访问控制。它是最终决定是否允许用户做某事的机制。和 一样Authenticator,Authorizer也知道如何协调多个后端数据源来访问角色和权限信息。在Authorizer使用该信息来准确确定是否允许用户执行特定的操作。)SessionManager (org.apache.shiro.session.mgt.SessionManager)The SessionManager knows how to create and manage user Session lifecycles to provide a robust Session experience for users in all environments. This is a unique feature in the world of security frameworks - Shiro has the ability to natively manage user Sessions in any environment, even if there is no Web/Servlet or EJB container available. By default, Shiro will use an existing session mechanism if available, (e.g. Servlet Container), but if there isn’t one, such as in a standalone application or non-web environment, it will use its built-in enterprise session management to offer the same programming experience. The SessionDAO exists to allow any datasource to be used to persist sessions.(SessionManager负责管理shiro自己封装的session的生命周期。)SessionDAO (org.apache.shiro.session.mgt.eis.SessionDAO)The SessionDAO performs Session persistence (CRUD) operations on behalf of the SessionManager. This allows any data store to be plugged in to the Session Management infrastructure.(SessionDAO执行Session持久代(CRUD)操作SessionManager。这允许将任何数据存储插入会话管理基础架构。)CacheManager (org.apache.shiro.cache.CacheManager)The CacheManager creates and manages Cache instance lifecycles used by other Shiro components. Because Shiro can access many back-end data sources for authentication, authorization and session management, caching has always been a first-class architectural feature in the framework to improve performance while using these data sources. Any of the modern open-source and/or enterprise caching products can be plugged in to Shiro to provide a fast and efficient user-experience.(CacheManager创建和管理Cache其他四郎组件使用实例的生命周期。由于 Shiro 可以访问许多后端数据源进行身份验证、授权和会话管理,因此缓存一直是框架中的一流架构特性,以在使用这些数据源时提高性能。任何现代开源和/或企业缓存产品都可以插入 Shiro,以提供快速高效的用户体验。)Cryptography (org.apache.shiro.crypto.*)Cryptography is a natural addition to an enterprise security framework. Shiro’s crypto package contains easy-to-use and understand representations of crytographic Ciphers, Hashes (aka digests) and different codec implementations. All of the classes in this package are carefully designed to be very easy to use and easy to understand. Anyone who has used Java’s native cryptography support knows it can be a challenging animal to tame. Shiro’s crypto APIs simplify the complicated Java mechanisms and make cryptography easy to use for normal mortal human beings.(Cryptography是企业安全框架的自然补充。Shiro 的crypto软件包包含易于使用和理解的密码学、哈希(又名摘要)和不同编解码器实现的表示。这个包中的所有类都经过精心设计,非常易于使用和理解。任何使用过 Java 本地加密支持的人都知道,驯服它可能是一种具有挑战性的动物。Shiro 的加密 API 简化了复杂的 Java 机制并使密码学易于普通人使用。)Realms (org.apache.shiro.realm.Realm)As mentioned above, Realms act as the ‘bridge’ or ‘connector’ between Shiro and your application’s security data. When it comes time to actually interact with security-related data like user accounts to perform authentication (login) and authorization (access control), Shiro looks up many of these things from one or more Realms configured for an application. You can configure as many Realms as you need (usually one per data source) and Shiro will coordinate with them as necessary for both authentication and authorization.(如上所述,Realms 充当 Shiro 和应用程序安全数据之间的“桥梁”或“连接器”。当需要与安全相关数据(如用户帐户)进行实际交互以执行身份验证(登录)和授权(访问控制)时,Shiro 从为应用程序配置的一个或多个 Realms 中查找其中的许多内容。您可以根据Realms需要配置任意数量(通常每个数据源一个),Shiro 将根据需要与他们协调进行身份验证和授权。)看了上面一大段肯定有头特了,到底是啥意思没搞明白,那直接来看个有史以来最简单的Shiro使用列子的代码吧:列子核心代码,至于导的是那个包啊,为什么我照着来的就不行呢,可以直接拉取我的代码看看,然后自己手动写一次,自己写一次完全不一样哦。** * @description: shiro最简单的学习,重点login()、checkRoles()里面源码最终都是通过realm来获取用户信息、角色、权限信息,以完成认证、授权 * @author: <a href="mailto:batis@foxmail.com">yanxizhu.com</a> * @date: 2021/6/25 22:24 * @version: 1.0 */ public class ShiroDemoT { SimpleAccountRealm simpleAccountRealm = new SimpleAccountRealm(); @Before public void addUser(){ simpleAccountRealm.addAccount("yanxi", "123456","admin","user"); } @Test public void shiroDt(){ //1、构建环境 DefaultSecurityManager securityManager = new DefaultSecurityManager(); securityManager.setRealm(simpleAccountRealm); //2、获取主体,提交认证请求 Subject subject = SecurityUtils.getSubject(); //认证 UsernamePasswordToken token= new UsernamePasswordToken("yanxi", "123456","admin"); subject.login(token); //是否认证成功 boolean authenticated = subject.isAuthenticated(); System.out.println("authenticated:"+authenticated); //角色校验 subject.checkRoles("admin","user"); //3、退出登录 subject.logout(); System.out.println("退出登录后-authenticated:"+authenticated); } }看完这段代码有没有豁然开朗,原来就这样的啊,上面的subject就是我们的主体,就是用网管分配的账号密码,那我么是怎么认证、授权的呢?怎么用的呢?用就是subject.login(token)这个了。那认证、授权呢?认证授权就是securityManager里面的2个方法了,一个方法负责认证,一个负责授权,而我们自定义的认证、授权规则是怎么样的呢?也就是上面的securityManager.setRealm(simpleAccountRealm)中的simpleAccountRealm了,具体securityManager是怎么实现认证、授权的呢?那就可以看看认证subject.login(token)、授权subject.checkRoles("admin","user")这2方法内部源码怎么实现的了。源码后面大体看一下。完整流程应该是这样的: 1、构建securityManager环境2、获得主体subject,怎么获得的,就是Shiro提供的SecurityUtils工具类型就获得了。3、主体subject是怎么使用认证的,非常简单subject.login(token)这样就完了。4、通过securityManager提供的认证、授权方法完成后,会返回主体subject拥有的角色、权限,我们通过subject.checkRoles("admin","user")就可以验证主体subject是否认证有对应的角色了,当然还有个校验是有有对应权限的方法//资源权限,删除用户权限subject.checkPermission("user:update")。上面这个简单的Shiro就完了,以后开发中simpleAccountRealm这个Realm就要我们自己去实现了,以及后面的认证、授权、校验是否有这个角色、权限那可能就要复杂一点了。到这里你应该明白Shiro的简单使用了吧,那我们看看另2种Realm的实现方法,一种通过读ini文件、一种通过jdbcRealm读数据库来实现simpleAccountRealm.addAccount("yanxi", "123456","admin","user")的列子吧:方式一、通过读取ini文件,实现我们的Realm,代码如下:/** * @description: 通过inir(配置用户角色,权限)的方法验证用户角色、资源权限,前提是要先登录成功,也就是认证成功 * @author: <a href="mailto:batis@foxmail.com">清风</a> * @date: 2021/6/25 22:24 * @version: 1.0 */ public class ShiroDemoT2 { @Test public void shiroDt(){ IniRealm ini = new IniRealm("classpath:user.ini"); //1、构建环境 DefaultSecurityManager securityManager = new DefaultSecurityManager(); ThreadContext.bind(securityManager); securityManager.setRealm(ini); //2、获取主体,提交认证请求 Subject subject = SecurityUtils.getSubject(); //认证 UsernamePasswordToken token= new UsernamePasswordToken("yanxi", "123456","admin"); subject.login(token); //是否认证成功 boolean authenticated = subject.isAuthenticated(); System.out.println("authenticated:"+authenticated); //角色校验,是否是admin角色 subject.checkRoles("admin"); //资源权限,删除用户权限 subject.checkPermission("user:update"); } }说明 :user.ini文件是放在我们的resource资源文件夹里面的一个文件,后缀为.ini,文件内容如何:[users] yanxi=123456,admin [roles] admin=user:delete,user:update方式二、通过jdbcRealm读数据库来实现,代码如下:/** * @description: 通过jdbcRealm(配置用户角色,权限)的方法验证用户角色、资源权限,前提是要先登录成功,也就是认证成功 * @author: <a href="mailto:batis@foxmail.com">清风</a> * @date: 2021/6/25 22:24 * @version: 1.0 */ public class ShiroDemoT3 { DruidDataSource dataSource = new DruidDataSource(); { dataSource.setUrl("jdbc:mysql://localhost:3306/test"); dataSource.setUsername("root"); dataSource.setPassword("root"); } @Test public void shiroDt(){ JdbcRealm jdbcRealm = new JdbcRealm(); jdbcRealm.setDataSource(dataSource); //1、构建环境 DefaultSecurityManager securityManager = new DefaultSecurityManager(); ThreadContext.bind(securityManager); securityManager.setRealm(jdbcRealm); //2、获取主体,提交认证请求 Subject subject = SecurityUtils.getSubject(); //认证 UsernamePasswordToken token= new UsernamePasswordToken("yanxi", "123456"); subject.login(token); //是否认证成功 boolean authenticated = subject.isAuthenticated(); System.out.println("authenticated:"+authenticated); //角色校验,是否是admin角色 subject.checkRoles("admin","user"); subject.checkRoles("user"); //资源权限,删除用户权限 subject.checkPermission("user:select"); } }说明:有人会说为什么没写sql查询就可以直接认证、授权了呢?因为jdbcRealm里面已经有这些的基本实现了,点开JdbcRealm源码,里面就可以看到如下代码了:public class JdbcRealm extends AuthorizingRealm { protected static final String DEFAULT_AUTHENTICATION_QUERY = "select password from users where username = ?"; protected static final String DEFAULT_SALTED_AUTHENTICATION_QUERY = "select password, password_salt from users where username = ?"; protected static final String DEFAULT_USER_ROLES_QUERY = "select role_name from user_roles where username = ?"; protected static final String DEFAULT_PERMISSIONS_QUERY = "select permission from roles_permissions where role_name = ?"; private static final Logger log = LoggerFactory.getLogger(JdbcRealm.class); protected DataSource dataSource; protected String authenticationQuery = "select password from users where username = ?"; protected String userRolesQuery = "select role_name from user_roles where username = ?"; protected String permissionsQuery = "select permission from roles_permissions where role_name = ?";当然我们还可以自己写的sql实现,代码如下:/** * @description: 通过jdbcRealm(配置用户角色,权限)的方法验证用户角色、资源权限,前提是要先登录成功,也就是认证成功 * @author: <a href="mailto:batis@foxmail.com">清风</a> * @date: 2021/6/25 22:24 * @version: 1.0 */ public class ShiroDemoT3 { DruidDataSource dataSource = new DruidDataSource(); { dataSource.setUrl("jdbc:mysql://localhost:3306/test"); dataSource.setUsername("root"); dataSource.setPassword("root"); } @Test public void shiroDt(){ JdbcRealm jdbcRealm = new JdbcRealm(); jdbcRealm.setDataSource(dataSource); //jdbcRealm不会默认查询资源权限,需要手动开启 jdbcRealm.setPermissionsLookupEnabled(true); // **这个地方就是自己写sql实现了** //jdbcRealm默认有查询语句,这里可以使用自己的sql查询 //用户sql String sql="select password from test_user where user_name=?"; jdbcRealm.setAuthenticationQuery(sql); //角色sql String sql2="select role_name from test_user_role where user_name=?"; jdbcRealm.setUserRolesQuery(sql2); //1、构建环境 DefaultSecurityManager securityManager = new DefaultSecurityManager(); ThreadContext.bind(securityManager); securityManager.setRealm(jdbcRealm); //2、获取主体,提交认证请求 Subject subject = SecurityUtils.getSubject(); //认证 // UsernamePasswordToken token= new UsernamePasswordToken("yanxi", "123456"); UsernamePasswordToken token= new UsernamePasswordToken("xixi", "654321"); subject.login(token); //是否认证成功 boolean authenticated = subject.isAuthenticated(); System.out.println("authenticated:"+authenticated); // //角色校验,是否是admin角色 // subject.checkRoles("admin","user"); subject.checkRoles("user"); // // //资源权限,删除用户权限 // subject.checkPermission("user:select"); } }权限的自定义同理,就不在写SQL建表了,贴一下数据库对应的表及结构,非常简单的表结构:默认的jdbcRealm使用的表: 自定义sql使用的表: 整体表结构: 好了,这个你应该明白了Shiro的整体过程了,那么我们就要写一个自定义的Realm了,一般开发中也是这样用法,代码如下:/** * @description: 自定义Realm完整认证 * @author: <a href="mailto:batis@foxmail.com">清风</a> * @date: 2021/6/26 0:16 * @version: 1.0 */ public class CustomRealmTest { @Test public void shiroDt(){ //自定义的Realm CustomRealm customRealm = new CustomRealm(); //1、构建环境 DefaultSecurityManager securityManager = new DefaultSecurityManager(); ThreadContext.bind(securityManager); securityManager.setRealm(customRealm); //设置加密信息 HashedCredentialsMatcher matcher = new HashedCredentialsMatcher(); //设置加密的名称 matcher.setHashAlgorithmName("md5"); //设置加密的次数 matcher.setHashIterations(1); //设置加密信息到Realm中 customRealm.setCredentialsMatcher(matcher); //2、获取主体,提交认证请求 Subject subject = SecurityUtils.getSubject(); //认证 UsernamePasswordToken token= new UsernamePasswordToken("xixi", "654321"); subject.login(token); //是否认证成功 boolean authenticated = subject.isAuthenticated(); System.out.println("authenticated:"+authenticated); //角色校验,是否是admin角色 subject.checkRoles("admin","user"); //资源权限,删除用户权限 subject.checkPermissions("user:delete","user.add"); } }说明: //设置加密信息 HashedCredentialsMatcher matcher = new HashedCredentialsMatcher(); //设置加密的名称 matcher.setHashAlgorithmName("md5"); //设置加密的次数 matcher.setHashIterations(1); //设置加密信息到Realm中 customRealm.setCredentialsMatcher(matcher);这里就是我们设置加密的地方,具体实现在自定义Realm类中。注意这里哦customRealm.setCredentialsMatcher(matcher);不然自定义Realm类中加密算法没有用到哦。这才是自定义Realm类的地方哦:/** * @description: 自定义Realm,为什么要继承AuthorizingRealm? * 因为默认的jdbcRealm就是重写AuthorizingRealm里面这2个方法完成认证和授权的 * @author: <a href="mailto:batis@foxmail.com">清风</a> * @date: 2021/6/26 0:02 * @version: 1.0 */ public class CustomRealm extends AuthorizingRealm { Map<String,String> userMap = new HashMap<String,String>(16); { //通过md5加密后,就不能使用铭文了,使用md5加密后的c33367701511b4f6020ec61ded352059 //md5加密方法,最下面的main临时方法 // userMap.put("xixi", "654321"); //md5加密后的密码 // userMap.put("xixi", "c33367701511b4f6020ec61ded352059"); //使用md5加盐后的密码 userMap.put("xixi", "87b441673e676a402074c349ef983c07"); super.setName("customRealm"); } /** * 自定义授权 * @param principalCollection * @return */ @Override protected AuthorizationInfo doGetAuthorizationInfo(PrincipalCollection principalCollection) { String userName = (String)principalCollection.getPrimaryPrincipal(); //通过用户名查询角色信息 Set<String> roles = getRolesByName(userName); //通过用户名查询权限信息 Set<String> permissions = getPermissionsByName(userName); //返回角色、资源信息 SimpleAuthorizationInfo simpleAuthorizationInfo = new SimpleAuthorizationInfo(); simpleAuthorizationInfo.setRoles(roles); simpleAuthorizationInfo.setStringPermissions(permissions); return simpleAuthorizationInfo; } /** * 自定义的认证 * @param authenticationToken * @return * @throws AuthenticationException */ @Override protected AuthenticationInfo doGetAuthenticationInfo(AuthenticationToken authenticationToken) throws AuthenticationException { //通过authenticationToken获取用户名 String userName = (String)authenticationToken.getPrincipal(); //获取密码 String password = getPasswordByName(userName); if(null == password){ return null; } //第一个用户名、密码、realm名称 SimpleAuthenticationInfo simpleAuthenticationInfo = new SimpleAuthenticationInfo(userName,password,"customRealm"); //使用md5加盐时,需要返回盐的名称,不适用盐时,不用加 //注意:如果盐名称和使用md5加盐时用的盐名称不一样,就不同通过认证哦,因为加密用的盐名称不一样肯定得到的加密密码不一样 simpleAuthenticationInfo.setCredentialsSalt(ByteSource.Util.bytes("yanxi")); return simpleAuthenticationInfo; } /** * 模拟数据库查询操作 * @param userName * @return */ public String getPasswordByName(String userName){ //这里通过mysql的基本查询获取密码,这里模拟不操作数据库了 return userMap.get(userName); } /** * 模拟从数据库查询角色信息 * @param userName * @return */ public Set<String> getRolesByName(String userName){ Set<String> roles = new HashSet<String>(16); roles.add("admin"); roles.add("user"); return roles; } /** * 模拟从数据库查询权限(资源)信息 * @param userName * @return */ public Set<String> getPermissionsByName(String userName){ Set<String> permissions = new HashSet<String>(16); permissions.add("user:delete"); permissions.add("user.add"); return permissions; } //md5计算出加密后的密码 // public static void main(String[] args) { // Md5Hash md5Hash = new Md5Hash("654321"); // System.out.println(md5Hash.toString()); // } //使用md5加盐后的计算结果,这种更安全.这里假设盐名称为yanxi public static void main(String[] args) { Md5Hash md5Hash = new Md5Hash("654321","yanxi"); System.out.println(md5Hash.toString()); } } 这里有人肯能会问为什么要extends AuthorizingRealm,那你看看之前最简单的例子里面是不是也是继承这个类啊,最主要原因是securityManager使用login进行认证、授权的具体实现都是在这里面,而我们实现自己的Realm,那就必须继承AuthorizingRealm,并重写里面的doGetAuthenticationInfo()认证方法、doGetAuthorizationInfo()授权方法。那我把关键代码在贴一下吧。 自定义认证、授权关键代码:/** * 自定义授权 * @param principalCollection * @return */ @Override protected AuthorizationInfo doGetAuthorizationInfo(PrincipalCollection principalCollection) { String userName = (String)principalCollection.getPrimaryPrincipal(); //通过用户名查询角色信息 Set<String> roles = getRolesByName(userName); //通过用户名查询权限信息 Set<String> permissions = getPermissionsByName(userName); //返回角色、资源信息 SimpleAuthorizationInfo simpleAuthorizationInfo = new SimpleAuthorizationInfo(); simpleAuthorizationInfo.setRoles(roles); simpleAuthorizationInfo.setStringPermissions(permissions); return simpleAuthorizationInfo; } /** * 自定义的认证 * @param authenticationToken * @return * @throws AuthenticationException */ @Override protected AuthenticationInfo doGetAuthenticationInfo(AuthenticationToken authenticationToken) throws AuthenticationException { //通过authenticationToken获取用户名 String userName = (String)authenticationToken.getPrincipal(); //获取密码 String password = getPasswordByName(userName); if(null == password){ return null; } //第一个用户名、密码、realm名称 SimpleAuthenticationInfo simpleAuthenticationInfo = new SimpleAuthenticationInfo(userName,password,"customRealm"); //使用md5加盐时,需要返回盐的名称,不适用盐时,不用加 //注意:如果盐名称和使用md5加盐时用的盐名称不一样,就不同通过认证哦,因为加密用的盐名称不一样肯定得到的加密密码不一样 simpleAuthenticationInfo.setCredentialsSalt(ByteSource.Util.bytes("yanxi")); return simpleAuthenticationInfo; }注意:自己看上面的自定义Realm类CustomRealm,里面的md5加密、加盐,以及模拟数据库的操作。 代码注意点一: super.setName("customRealm");这里设置的自定义Realm名称要和认证中返回的名称一致。//第一个用户名、密码、realm名称SimpleAuthenticationInfo simpleAuthenticationInfo = new SimpleAuthenticationInfo(userName,password,"customRealm"); 代码注意点二: Md5Hash md5Hash = new Md5Hash("654321","yanxi");加密时使用的盐名称要和我们认证返回信息中设置的盐名称一致。simpleAuthenticationInfo.setCredentialsSalt(ByteSource.Util.bytes("yanxi"));此时我们数据库存在就是md5+加盐后加密的密码87b441673e676a402074c349ef983c07,这里只是模拟了数据库的操作,实际中肯定是使用dao层的数据库操作完成。到这里你应该知道Shiro怎么使用了,以及Shiro里面怎么实现加密,怎么自定义Realm了。最后我们看一下subject.login(token)、subject.checkRoles("admin","user")、subject.checkPermissions("user:delete","user.add")内部源码怎么用到我们自定义Realm类CustomRealm的:login认证源码:public void login(AuthenticationToken token) throws AuthenticationException { this.clearRunAsIdentitiesInternal(); Subject subject = this.securityManager.login(this, token); String host = null; PrincipalCollection principals; if (subject instanceof DelegatingSubject) { DelegatingSubject delegating = (DelegatingSubject)subject; principals = delegating.principals; host = delegating.host; } else { principals = subject.getPrincipals(); } if (principals != null && !principals.isEmpty()) { this.principals = principals; this.authenticated = true; if (token instanceof HostAuthenticationToken) { host = ((HostAuthenticationToken)token).getHost(); } if (host != null) { this.host = host; } Session session = subject.getSession(false); if (session != null) { this.session = this.decorate(session); } else { this.session = null; } } else { String msg = "Principals returned from securityManager.login( token ) returned a null or empty value. This value must be non null and populated with one or more elements."; throw new IllegalStateException(msg); } }重点看:Subject subject = this.securityManager.login(this, token);点击login跟进去看代码如下: public Subject login(Subject subject, AuthenticationToken token) throws AuthenticationException { AuthenticationInfo info; try { info = this.authenticate(token); } catch (AuthenticationException var7) { AuthenticationException ae = var7; try { this.onFailedLogin(token, ae, subject); } catch (Exception var6) { if (log.isInfoEnabled()) { log.info("onFailedLogin method threw an exception. Logging and propagating original AuthenticationException.", var6); } } throw var7; } Subject loggedIn = this.createSubject(token, info, subject); this.onSuccessfulLogin(token, info, loggedIn); return loggedIn; }重点看:info = this.authenticate(token);authenticate方法继续跟进代码: public AuthenticationInfo authenticate(AuthenticationToken token) throws AuthenticationException { return this.authenticator.authenticate(token); }继续跟进this.authenticator.authenticate(token);代码:public final AuthenticationInfo authenticate(AuthenticationToken token) throws AuthenticationException { if (token == null) { throw new IllegalArgumentException("Method argument (authentication token) cannot be null."); } else { log.trace("Authentication attempt received for token [{}]", token); AuthenticationInfo info; try { info = this.doAuthenticate(token); if (info == null) { String msg = "No account information found for authentication token [" + token + "] by this " + "Authenticator instance. Please check that it is configured correctly."; throw new AuthenticationException(msg); } } catch (Throwable var8) { AuthenticationException ae = null; if (var8 instanceof AuthenticationException) { ae = (AuthenticationException)var8; } if (ae == null) { String msg = "Authentication failed for token submission [" + token + "]. Possible unexpected " + "error? (Typical or expected login exceptions should extend from AuthenticationException)."; ae = new AuthenticationException(msg, var8); if (log.isWarnEnabled()) { log.warn(msg, var8); } } try { this.notifyFailure(token, ae); } catch (Throwable var7) { if (log.isWarnEnabled()) { String msg = "Unable to send notification for failed authentication attempt - listener error?. Please check your AuthenticationListener implementation(s). Logging sending exception and propagating original AuthenticationException instead..."; log.warn(msg, var7); } } throw ae; } log.debug("Authentication successful for token [{}]. Returned account [{}]", token, info); this.notifySuccess(token, info); return info; } }重点看:info = this.doAuthenticate(token);继续跟进代码如下: protected AuthenticationInfo doAuthenticate(AuthenticationToken authenticationToken) throws AuthenticationException { this.assertRealmsConfigured(); Collection<Realm> realms = this.getRealms(); return realms.size() == 1 ? this.doSingleRealmAuthentication((Realm)realms.iterator().next(), authenticationToken) : this.doMultiRealmAuthentication(realms, authenticationToken); }重点看这,这里最终还是使用realms来获取我们的角色、资源数据。Collection<Realm> realms = this.getRealms(); return realms.size() == 1 ? this.doSingleRealmAuthentication((Realm)realms.iterator().next(), authenticationToken) : this.doMultiRealmAuthentication(realms, authenticationToken);接下来看看subject.checkRoles("admin","user")的源码:subject.checkRoles("admin","user");继续跟进代码: public void checkRoles(String... roleIdentifiers) throws AuthorizationException { this.assertAuthzCheckPossible(); this.securityManager.checkRoles(this.getPrincipals(), roleIdentifiers); }this.securityManager.checkRoles(this.getPrincipals(), roleIdentifiers);继续跟进代码:public void checkRoles(PrincipalCollection principals, String... roles) throws AuthorizationException { this.assertRealmsConfigured(); if (roles != null) { String[] var3 = roles; int var4 = roles.length; for(int var5 = 0; var5 < var4; ++var5) { String role = var3[var5]; this.checkRole(principals, role); } } }this.checkRole(principals, role);继续跟进代码: public void checkRole(PrincipalCollection principals, String role) throws AuthorizationException { this.assertRealmsConfigured(); if (!this.hasRole(principals, role)) { throw new UnauthorizedException("Subject does not have role [" + role + "]"); } }this.hasRole(principals, role)继续跟进代码:public boolean hasRole(PrincipalCollection principals, String roleIdentifier) { this.assertRealmsConfigured(); Iterator var3 = this.getRealms().iterator(); Realm realm; do { if (!var3.hasNext()) { return false; } realm = (Realm)var3.next(); } while(!(realm instanceof Authorizer) || !((Authorizer)realm).hasRole(principals, roleIdentifier)); return true; }这里也可以看出是通过realm来实现授权的。所以我们只需要自定义realm中的认证、授权方法即可。有些理解不对的还请谅解,谢谢。最后附上Github代码地址:https://github.com/willxwu/shiro-learn